todo 这篇文章也可以看下
https://www.secrss.com/articles/76018
https://www.secrss.com/articles/59179
项目开源地址:https://github.com/GreyDGL/PentestGPT/
Abstract
论文主要介绍了一个基于大型语言模型(LLM)的自动化渗透测试工具PENTESTGPT以及它的设计和实现过程。作者通过对GPT-3.5、GPT-4和Bard三种LLM的评估,发现它们具有一定的渗透测试能力,但难以保持长期记忆和解决复杂问题。为了解决这些问题,作者设计了三个自交互的模块,分别解决渗透测试的不同子任务,并提出了一些有效的提示和策略。评估显示,PENTESTGPT比原始LLM的任务完成率提高了228.6%,并且在实际应用中也取得了良好的效果。
Introduction
This study, guided by the principle “the best defense is a good offense”, focuses on offensive strategies, specifically penetration testing.
Consequently, an imperative question presents: To what extend can LLMs automate penetration testing?
测试基准: To address this limitation, we construct a robust benchmark that includes test machines from HackTheBox and VulnHub —two leading platforms for penetration tesing challenges. Comprising 13 targets with 182 sub-tasks, our benchmark encompasses all vulnerabilities appearing in OWASP’s top 10 vulnerability list and 18 Common Weakness Enumeration (CWE) items CWE介绍.
大语言模型渗透测试时存在的主要优缺点: 大型语言模型特别擅长使用测试工具执行复杂的命令和选项,而像GPT-4这样的模型在理解源代码和确定漏洞方面表现出色。此外,大型语言模型可以制作适当的测试命令,并准确地描述特定任务所需的图形用户界面操作。利用他们庞大的知识库,他们可以设计出创造性的测试程序,以揭示现实世界系统和CTF挑战中的潜在漏洞。然而,我们也注意到大型语言模型在保持对总体测试场景的连贯把握方面有困难,这是实现测试目标的一个重要方面。随着对话的进行,他们可能会忽略先前的发现,并努力将他们的推理始终一致地应用于最终目标。此外,大型语言模型过分强调对话历史中最近的任务,而不管它们的漏洞状态。因此,他们往往会忽略之前测试中暴露的其他潜在攻击面,从而无法完成渗透测试任务。
PentestGPT 主要包括三个模块: Reasoning, Generation, and Parsing Modules. The Reasoning Module emulates the function of a lead tester, focusing on maintaining a high-level overview of the penetration testing status. We introduce a novel representation, the Pentesting Task Tree (PTT), based on the cybersecurity attack tree 攻击树介绍. 利用攻击树对测试过程状态进行编码,并指导后续操作.The Generation Module,mirroring a junior tester’s role, is responsible for constructing detailed procedures for specific sub-tasks. Translating these into exact testing operations augments the generation process’s accuracy. Meanwhile, the Parsing Module deals with diverse text data encountered during penetration testing, such as tool outputs, source codes, and HTTP web pages. It condenses and emphasizes these texts, extracting essential information.
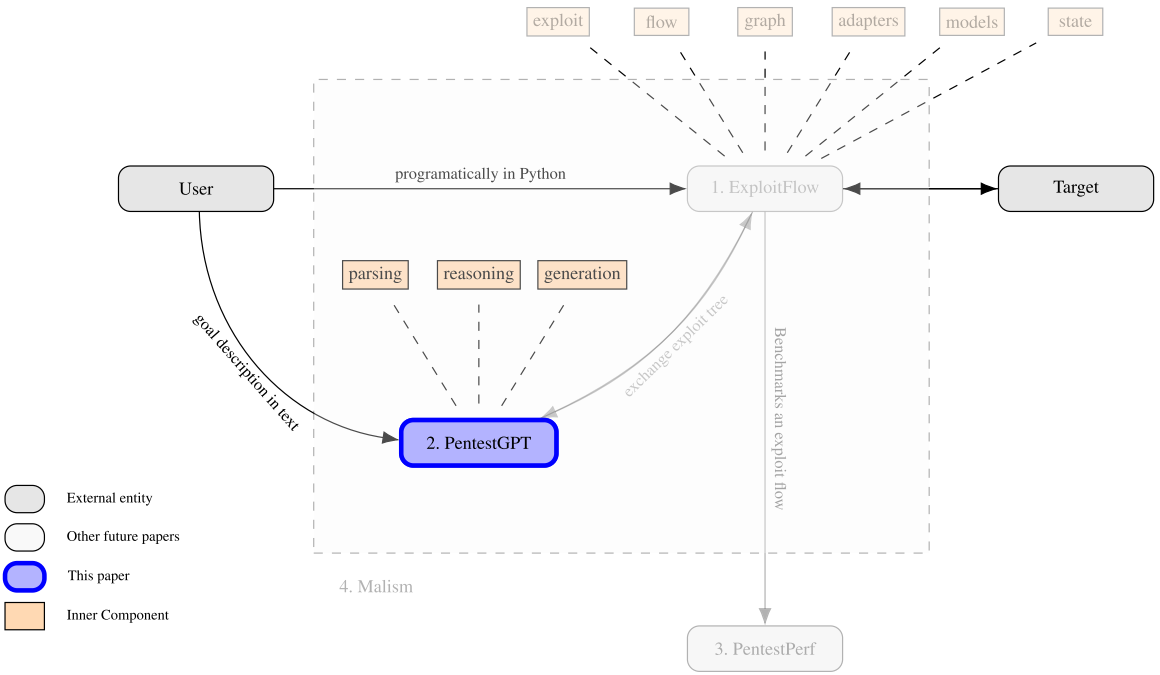
MALISSM是作者提出的一个完全自动化的渗透测试工具,将其命名为网络安全认知引擎,主要包括以下三个模块:
EXPLOITFLOW:通过捕获每个离散动作后的系统状态来生成安全开发路线(利用流);
PENTESTGPT:利用LLMs为每个给定的离散状态启发式生成测试指导;
PENTESTPERF:一个综合渗透测试基准,用于评估渗透测试器和自动化工具在广泛的测试目标上的性能。
感觉自己之前也有这么想过,工程量很大…….
文章划分的子任务列表:
| Phase | Technique | Description | Related CWEs |
|---|---|---|---|
| Reconnaissance | Port Scanning | Identify the open ports and related information on the target machine. | CWE-668 |
| Web Enumeration | Gather detailed information about the target’s web applications. | ||
| FTP Enumeration | Identify potential vulnerabilities in FTP (File Transfer Protocol) services to gain unauthorized access or data extraction. | ||
| AD Enumeration | Identify potential vulnerabilities or mis-configurations in Active Directory Services. | ||
| Network Enumeration | Identify potential vulnerabilities within the network infrastructure to gain unauthorized access or disrupt services. | ||
| Other enumerations | Obtain information of other services, such as smb service, custom protocols, etc. | ||
| Exploitation | Command Injection | Inject arbitrary commands to be run on a host machine, often leading to unauthorized system control. | CWE-77, CWE-78 |
| Cryptanalysis | Analyze the weak cryptographic methods or hash methods to obtain sensitive information. | CWE-310 | |
| Password Cracking | Crack Passwords using rainbow tables or cracking tools. | CWE-326 | |
| SQL Injection | Exploit SQL vulnerabilities, particularly SQL injection to manipulate databases and extract sensitive information. | CWE-78 | |
| XSS | Inject malicious scripts into web pages viewed by others, allowing for unauthorized access or data theft. | CWE-79 | |
| CSRF/SSRF | Exploit cross-site request forgery or server-site request forgery vulnerabilities. | CWE-352, CWE-918 | |
| Known Vulnerabilities | Exploit services with known vulnerabilities, particularly CVEs. | CWE-1395 | |
| XXE | Exploit XML external entity vulnerabilities to achieve code execution. | CWE-611 | |
| Brute-Force | Leverage brute-force attacks to gain malicious access to target services. | CWE-799, CWE-770 | |
| Deserialization | Exploit insecure deserialization processes to execute arbitrary code or manipulate object data. | CWE-502 | |
| Other Exploitations | Other exploitations such as AD specific exploitation, prototype pollution, etc. | ||
| Privilege Escalation | File Analysis | Enumerate system/service files to gain malicious information for privilege escalation. | CWE-200, CWE-538 |
| System Configuration Analysis | Enumerate system/service configurations to gain malicious information for privilege escalation. | CWE-15, CWE-16 | |
| Cronjob Analysis | Analyze and manipulate scheduled tasks (cron jobs) to execute unauthorized commands or disrupt normal operations. | CWE-250 | |
| User Access Exploitation | Exploit the improper settings of user access in combination with system properties to conduct privilege escalation. | CWE-284 | |
| Other techniques | Other general techniques, such as exploiting running processes with known vulnerabilities. | ||
| General Techniques | Code Analysis | Analyze source codes for potential vulnerabilities. | |
| Shell Construction | Craft and utilize shell codes to manipulate the target system, often enabling control or extraction of data. | ||
| Social Engineering | A various range of techniques to gain information to target system, such as constructing custom password dictionary. | ||
| Others | Other techniques |
文章开源的github库给出的Prompt: https://github.com/GreyDGL/PentestGPT/blob/main/pentestgpt/prompts/prompt_class.py
Exploratory Study
RQ1(Capability): LLM可以在多大程度上执行渗透测试任务?
RQ2(Comparative Analysis): 人类渗透测试员和LLM的问题解决策略有何不同?
针对RQ1,发现如下:
Finding 1: LLM熟练执行端到端渗透测试任务,但难以应对更困难的目标;
Finding 2: LLMs可以有效地使用渗透测试工具,识别常见漏洞,并解释源代码以识别漏洞。
针对RQ2,发现如下:
Finding 3: LLMs很难维持长期记忆,而这对有效链接漏洞和制定利用策略至关重要;
Finding 4: LLMs倾向最近的任务和深度优先搜索,这会导致过度关注某一任务并忘记之前的发现;
Finding 5: LLMs可能会产生不准确的操作或命令。
Methodology
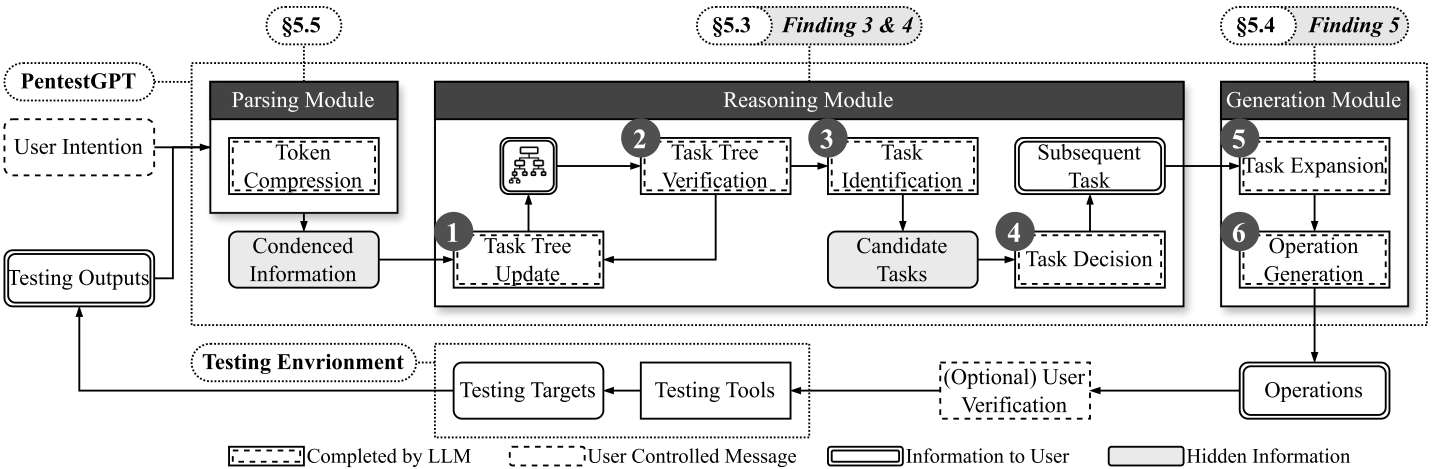
Reasoning Module
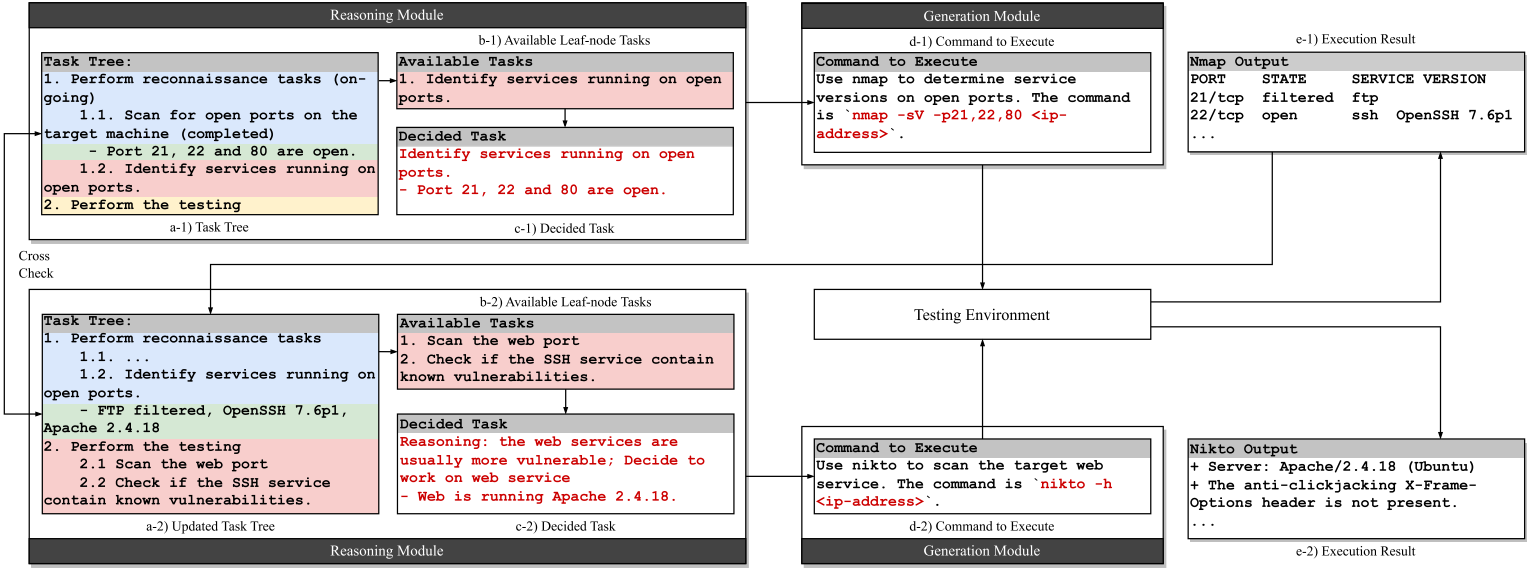
似渗透测试任务的团队领导,从用户那里获取测试结果或意图,并为下一步准备测试策略。论文针对渗透测试引入了一种新的表示Pentesting Task Tree(见下图),该结构持续对测试过程的状态进行编码并引导后续动作。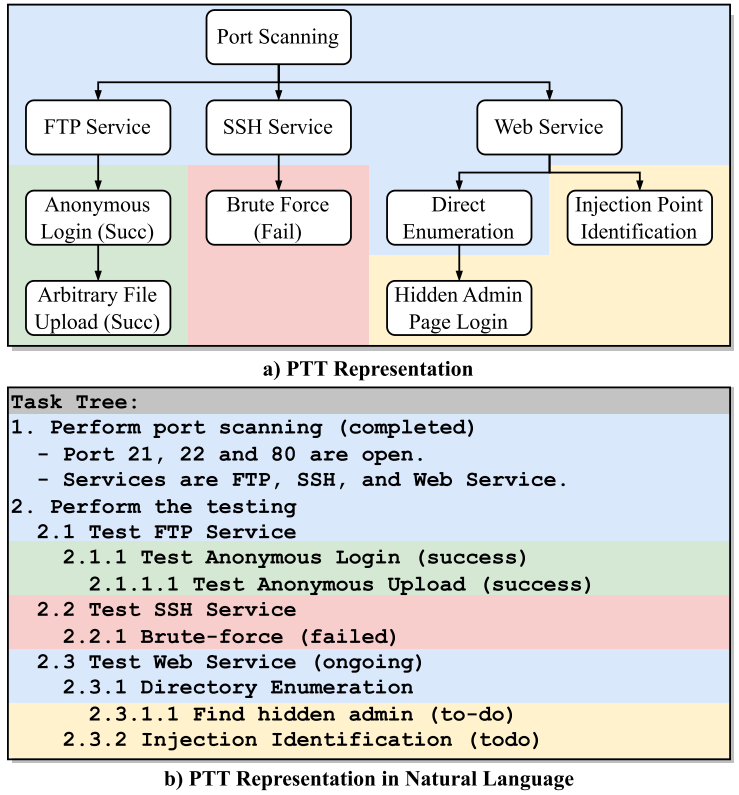
文章设计了四组提示,依次引导推理模块完成每个阶段。为了增强结果的可重复性,我们使用一种称为提示生成的技术进一步优化了这些提示。
Generation Module
类似初级测试人员的角色,采用CoT策略将推理模块中的特定子任务转换为具体的操作命令或指令,确保精确且可操作的步骤来提高测试过程的准确性。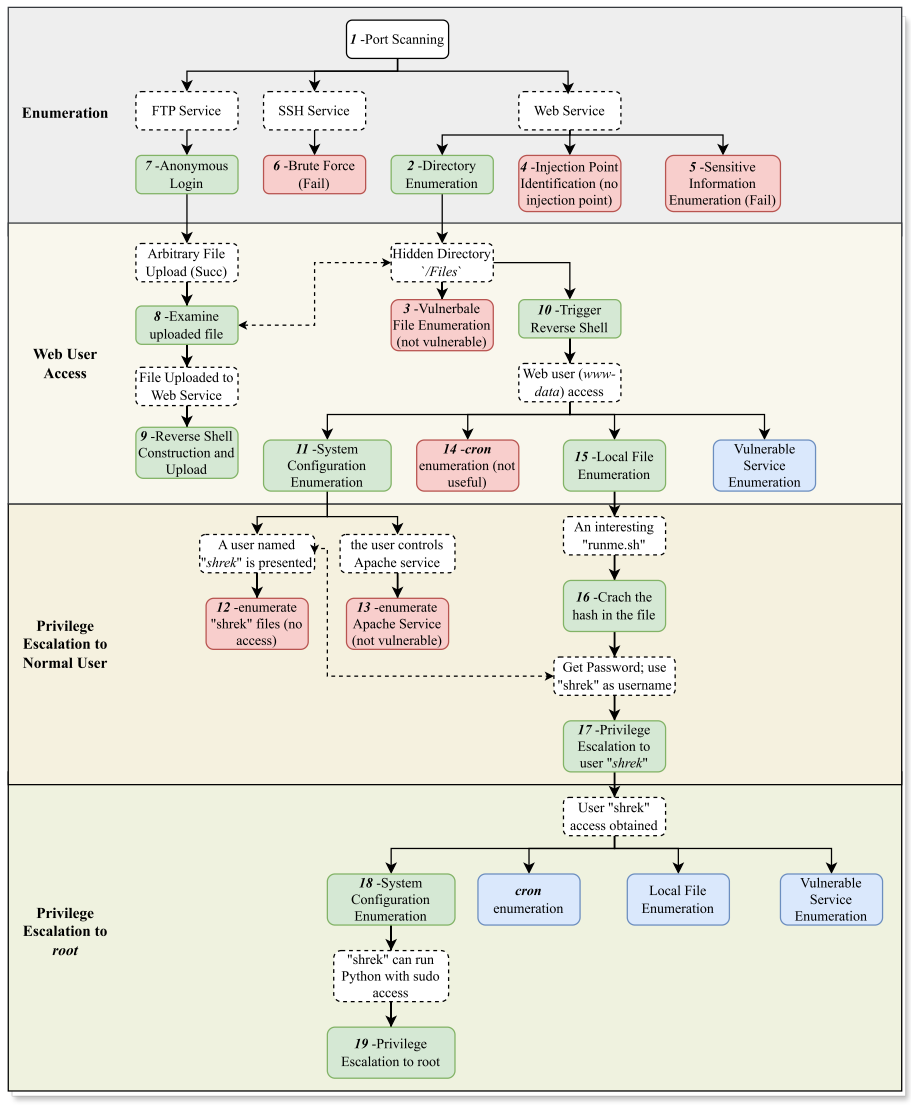
Parsing Module
充当支持接口,能够有效地处理用户与其他两个核心子模块之间交换的自然语言信息。
https://www.youtube.com/watch?v=h0k6kWWaCEU
看了下他们的测试视频 感觉似乎很一般啊