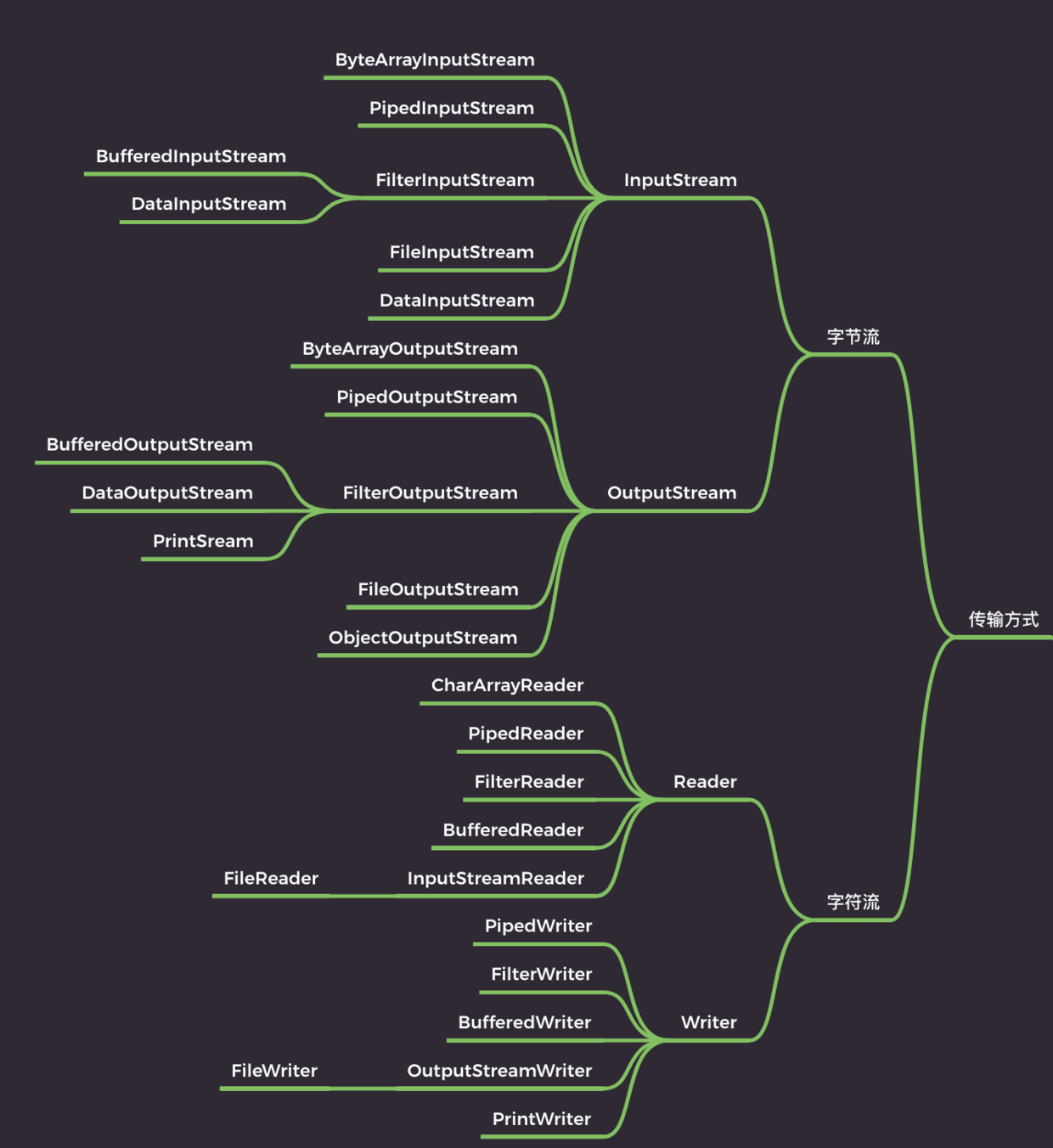
基础
Java IO(输入/输出)是 Java 编程语言中处理输入和输出操作的一部分,它位于 java.io 包中。这个包提供了丰富的类和接口,用于读写数据到文件、网络连接或其他源。
Java IO 的主要组成
Java IO 主要可以分为两大类:流(Stream)和读写器(Reader/Writer)。其实也就是按照传输方式划分可以分为:按字节传输、按字符传输,通常来说,一个字母或一个字符占用一个字节,一个汉字占用两个字节,具体还要看字符编码,比如说在 UTF-8 编码下,一个英文字母(不分大小写)为一个字节,一个中文汉字为三个字节;在 Unicode 编码中,一个英文字母为一个字节,一个中文汉字为两个字节。
字节流用来处理二进制文件,比如说图片啊、MP3 啊、视频啊。
字符流用来处理文本文件,文本文件可以看作是一种特殊的二进制文件,只不过经过了编码,便于人们阅读。
换句话说就是,字节流可以处理一切文件,而字符流只能处理文本。字节流本身没有缓冲区,缓冲字节流相对于字节流,效率提升非常高。而字符流本身就带有缓冲区,缓冲字符流相对于字符流效率提升就不是那么大了。
流(Stream)
- 字节流:以字节为单位处理数据。主要类包括
InputStream和OutputStream。 - 过滤流:在输入或输出流上提供额外的功能,如缓冲、数据转换等。常见的过滤流包括
BufferedInputStream和BufferedOutputStream。
- 字节流:以字节为单位处理数据。主要类包括
读写器(Reader/Writer)
- 字符流:以字符为单位处理数据,更适合处理文本数据。主要类包括
Reader和Writer。 - 转换流:
InputStreamReader和OutputStreamWriter,它们可以将字节流和字符流之间进行转换。
- 字符流:以字符为单位处理数据,更适合处理文本数据。主要类包括
InputStream 类
int read():读取数据int read(byte b[], int off, int len):从第 off 位置开始读,读取 len 长度的字节,然后放入数组 b 中long skip(long n):跳过指定个数的字节int available():返回可读的字节数void close():关闭流,释放资源
OutputStream 类
void write(int b): 写入一个字节,虽然参数是一个 int 类型,但只有低 8 位才会写入,高 24 位会舍弃void write(byte b[], int off, int len): 将数组 b 中的从 off 位置开始,长度为 len 的字节写入void flush(): 强制刷新,将缓冲区的数据写入void close():关闭流
Reader 类
int read():读取单个字符int read(char cbuf[], int off, int len):从第 off 位置开始读,读取 len 长度的字符,然后放入数组 b 中long skip(long n):跳过指定个数的字符int ready():是否可以读了void close():关闭流,释放资源
Writer 类
void write(int c): 写入一个字符- `void write( char cbuf[], int off, int len): 将数组 cbuf 中的从 off 位置开始,长度为 len 的字符写入
void flush(): 强制刷新,将缓冲区的数据写入void close():关闭流
常用的 Java IO 类
File:代表文件和目录路径名的抽象表示形式。FileInputStream/FileOutputStream:用于读取和写入文件数据的字节流。BufferedReader/BufferedWriter:提供缓冲的字符流,增加效率。PrintWriter:具有自动行刷新的字符输出流,可以输出不同数据类型的格式化表示。
示例代码
下面是使用 Java IO 类进行文件读写的基本示例:
1 | import java.io.*; |
在算法中的使用
Java IO 在算法中常用于数据的读取和写入,比如从文件读取数据进行处理,或将处理结果写入文件。例如,在数据分析、日志处理和大数据处理中,频繁的文件读写操作是必不可少的。使用缓冲流(如 BufferedReader 和 BufferedWriter)可以显著提高读写效率。
操作对象划分
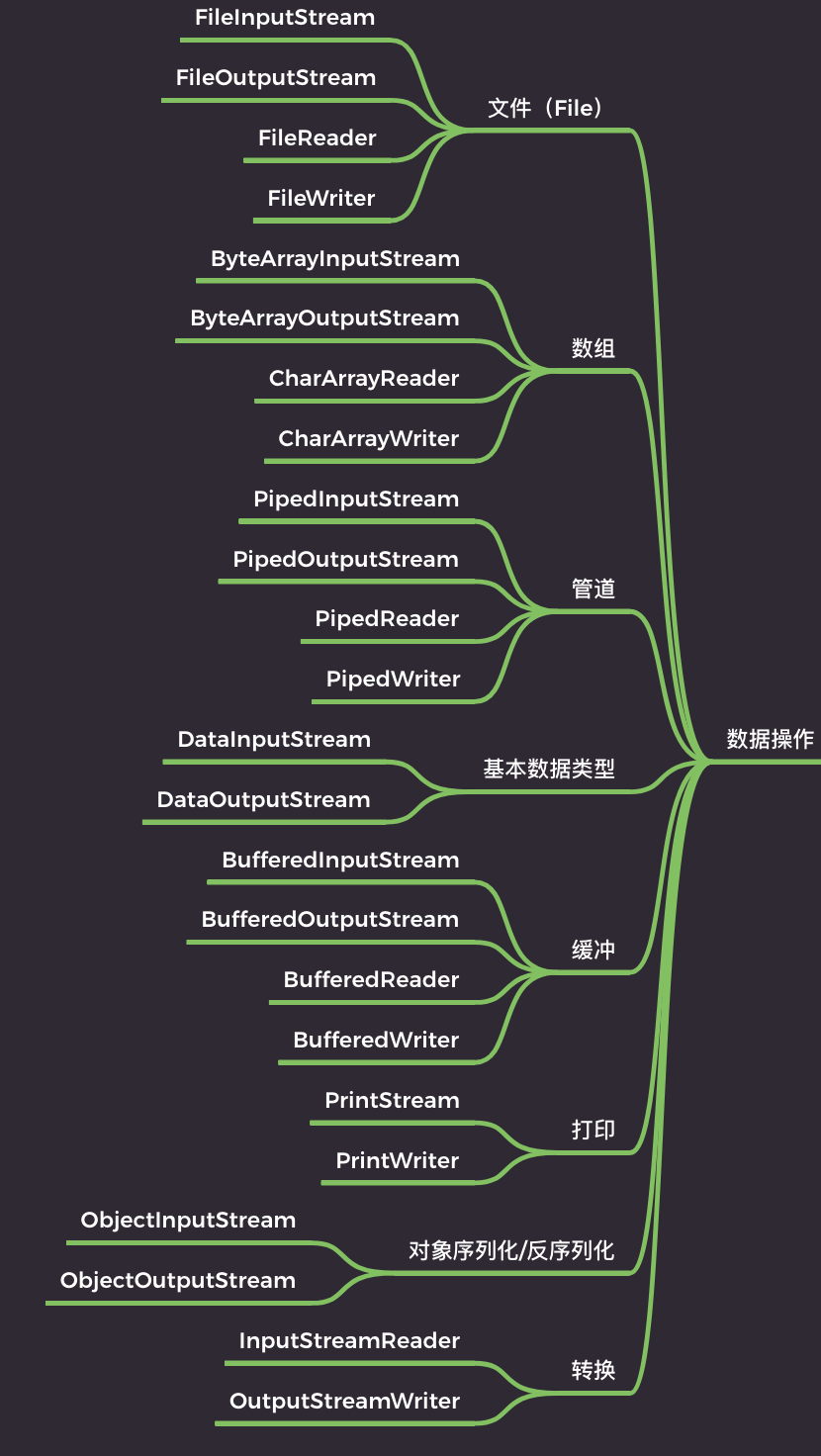
文件操作算是 IO 中最典型的操作了,也是最频繁的操作。那其实你可以换个角度来思考,比如说按照 IO 的操作对象来思考,IO 就可以分类为:文件、数组、管道、基本数据类型、缓冲、打印、对象序列化/反序列化,以及转换等。
Java Flie
java.io.File 类是专门对文件进行操作的类,注意只能对文件本身进行操作,不能对文件内容进行操作,想要操作内容,必须借助输入输出流。
构造方法
1 | // 文件路径名 |
- 一个 File 对象代表硬盘中实际存在的一个文件或者目录。
- File 类的构造方法不会检验这个文件或目录是否真实存在,因此无论该路径下是否存在文件或者目录,都不影响 File 对象的创建。
常用方法
File 的常用方法主要分为获取功能、获取绝对路径和相对路径、判断功能、创建删除功能的方法。
- 获取功能的方法
1
2
3
4
5
6
7
8
9
10
11File f = new File("/Users/username/aaa/bbb.java");
System.out.println("文件绝对路径:"+f.getAbsolutePath());
System.out.println("文件构造路径:"+f.getPath());
System.out.println("文件名称:"+f.getName());
System.out.println("文件长度:"+f.length()+"字节");
File f2 = new File("/Users/username/aaa");
System.out.println("目录绝对路径:"+f2.getAbsolutePath());
System.out.println("目录构造路径:"+f2.getPath());
System.out.println("目录名称:"+f2.getName());
System.out.println("目录长度:"+f2.length()); - 绝对路径和相对路径
1
2
3
4
5
6
7// 绝对路径示例
File absoluteFile = new File("/Users/username/example/test.txt");
System.out.println("绝对路径:" + absoluteFile.getAbsolutePath());
// 相对路径示例
File relativeFile = new File("example/test.txt");
System.out.println("相对路径:" + relativeFile.getPath()); - 判断功能的方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22File file = new File("/Users/username/example");
// 判断文件或目录是否存在
if (file.exists()) {
System.out.println("文件或目录存在");
} else {
System.out.println("文件或目录不存在");
}
// 判断是否是目录
if (file.isDirectory()) {
System.out.println("是目录");
} else {
System.out.println("不是目录");
}
// 判断是否是文件
if (file.isFile()) {
System.out.println("是文件");
} else {
System.out.println("不是文件");
} - 创建、删除功能的方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22// 创建文件
File file = new File("/Users/username/example/test.txt");
if (file.createNewFile()) {
System.out.println("创建文件成功:" + file.getAbsolutePath());
} else {
System.out.println("创建文件失败:" + file.getAbsolutePath());
}
// 删除文件
if (file.delete()) {
System.out.println("删除文件成功:" + file.getAbsolutePath());
} else {
System.out.println("删除文件失败:" + file.getAbsolutePath());
}
// 创建多级目录
File directory = new File("/Users/username/example/subdir1/subdir2");
if (directory.mkdirs()) {
System.out.println("创建目录成功:" + directory.getAbsolutePath());
} else {
System.out.println("创建目录失败:" + directory.getAbsolutePath());
} - 遍历目录
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19File directory = new File("/Users/itwanger/Documents/Github/paicoding");
// 列出目录下的文件名
String[] files = directory.list();
System.out.println("目录下的文件名:");
for (String file : files) {
System.out.println(file);
}
// 列出目录下的文件和子目录
File[] filesAndDirs = directory.listFiles();
System.out.println("目录下的文件和子目录:");
for (File fileOrDir : filesAndDirs) {
if (fileOrDir.isFile()) {
System.out.println("文件:" + fileOrDir.getName());
} else if (fileOrDir.isDirectory()) {
System.out.println("目录:" + fileOrDir.getName());
}
} - 递归遍历
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public static void main(String[] args) {
File directory = new File("/Users/itwanger/Documents/Github/paicoding");
// 递归遍历目录下的文件和子目录
traverseDirectory(directory);
}
public static void traverseDirectory(File directory) {
// 列出目录下的所有文件和子目录
File[] filesAndDirs = directory.listFiles();
// 遍历每个文件和子目录
for (File fileOrDir : filesAndDirs) {
if (fileOrDir.isFile()) {
// 如果是文件,输出文件名
System.out.println("文件:" + fileOrDir.getName());
} else if (fileOrDir.isDirectory()) {
// 如果是目录,递归遍历子目录
System.out.println("目录:" + fileOrDir.getName());
traverseDirectory(fileOrDir);
}
}
}
RandomAccessFile
RandomAccessFile 是 Java 中一个非常特殊的类,它既可以用来读取文件,也可以用来写入文件。与其他 IO 类(如 FileInputStream 和 FileOutputStream)不同,RandomAccessFile 允许您跳转到文件的任何位置,从那里开始读取或写入。这使得它特别适用于需要在文件中随机访问数据的场景,如数据库系统。
1 | import java.io.IOException; |
RandomAccessFile 主要有两个构造方法:
RandomAccessFile(File file, String mode):使用给定的文件对象和访问模式创建一个新的 RandomAccessFile 实例。RandomAccessFile(String name, String mode):使用给定的文件名和访问模式创建一个新的 RandomAccessFile 实例。
访问模式 mode 的值可以是:
- “r”:以只读模式打开文件。调用结果对象的任何 write 方法都将导致 IOException。
- “rw”:以读写模式打开文件。如果文件不存在,它将被创建。
- “rws”:以读写模式打开文件,并要求对内容或元数据的每个更新都被立即写入到底层存储设备。这种模式是同步的,可以确保在系统崩溃时不会丢失数据。
- “rwd”:与“rws”类似,以读写模式打开文件,但仅要求对文件内容的更新被立即写入。元数据可能会被延迟写入。
主要方法
long getFilePointer():返回文件指针的当前位置。long length():返回此文件的长度。int read():从该文件中读取一个字节数据。int read(byte[] b):从该文件中读取字节数据并将其存储到指定的字节数组中。int read(byte[] b, int off, int len):从该文件中读取字节数据并将其存储到指定的字节数组中,从偏移量 off 开始,最多读取 len 个字节。String readLine():从该文件中读取一行文本。readUTF():从文件读取 UTF-8 编码的字符串。此方法首先读取两个字节的长度信息,然后根据这个长度读取字符串的 UTF-8 字节。最后,这些字节被转换为 Java 字符串。这意味着当你使用 readUTF 方法读取字符串时,需要确保文件中的字符串是使用 writeUTF 方法写入的,这样它们之间的长度信息和编码方式才能保持一致。void seek(long pos):将文件指针设置到文件中的 pos 位置。void write(byte[] b):将指定的字节数组的所有字节写入该文件。void write(byte[] b, int off, int len):将指定字节数组的部分字节写入该文件,从偏移量 off 开始,写入 len 个字节。void write(int b):将指定的字节写入该文件。writeUTF(String str):将一个字符串以 UTF-8 编码写入文件。此方法首先写入两个字节的长度信息,表示字符串的 UTF-8 字节长度,然后写入 UTF-8 字节本身。因此,当你使用 writeUTF 写入字符串时,实际写入的字节数会比字符串的 UTF-8 字节长度多两个字节。这两个字节用于在读取字符串时确定正确的字符串长度。
再来看一个示例,结合前面的讲解,就会彻底掌握 RandomAccessFile。
1 | File file = new File("logs/javabetter/itwanger.txt"); |
Apache FileUtils 类
FileUtils 类是 Apache Commons IO 库中的一个类,提供了一些更为方便的方法来操作文件或目录。
1)复制文件或目录:
1 | File srcFile = new File("path/to/src/file"); |
2)删除文件或目录:
1 | File file = new File("path/to/file"); |
需要注意的是,如果要删除一个非空目录,需要先删除目录中的所有文件和子目录。
3)移动文件或目录:
1 | File srcFile = new File("path/to/src/file"); |
4)查询文件或目录的信息:
1 | File file = new File("path/to/file"); |
Hutool FileUtil 类
FileUtil 类是 Hutool 工具包中的文件操作工具类,提供了一系列简单易用的文件操作方法,可以帮助 Java 开发者快速完成文件相关的操作任务。
FileUtil 类包含以下几类操作工具:
- 文件操作:包括文件目录的新建、删除、复制、移动、改名等
- 文件判断:判断文件或目录是否非空,是否为目录,是否为文件等等。
- 绝对路径:针对 ClassPath 中的文件转换为绝对路径文件。
- 文件名:主文件名,扩展名的获取
- 读操作:包括 getReader、readXXX 操作
- 写操作:包括 getWriter、writeXXX 操作
下面是 FileUtil 类中一些常用的方法:
1、copyFile:复制文件。该方法可以将指定的源文件复制到指定的目标文件中。
1 | File dest = FileUtil.file("FileUtilDemo2.java"); |
2、move:移动文件或目录。该方法可以将指定的源文件或目录移动到指定的目标文件或目录中。
1 | FileUtil.move(file, dest, true); |
3、del:删除文件或目录。该方法可以删除指定的文件或目录,如果指定的文件或目录不存在,则会抛出异常。
1 | FileUtil.del(file); |
4、rename:重命名文件或目录。该方法可以将指定的文件或目录重命名为指定的新名称。
1 | FileUtil.rename(file, "FileUtilDemo3.java", true); |
5、readLines:从文件中读取每一行数据。
1 | FileUtil.readLines(file, "UTF-8").forEach(System.out::println); |
Java 缓冲流
Java 的缓冲流是对字节流和字符流的一种封装,通过在内存中开辟缓冲区来提高 I/O 操作的效率。Java 通过 BufferedInputStream 和 BufferedOutputStream 来实现字节流的缓冲,通过 BufferedReader 和 BufferedWriter 来实现字符流的缓冲。
缓冲流的工作原理是将数据先写入缓冲区中,当缓冲区满时再一次性写入文件或输出流,或者当缓冲区为空时一次性从文件或输入流中读取一定量的数据。这样可以减少系统的 I/O 操作次数,提高系统的 I/O 效率,从而提高程序的运行效率。
字节缓冲流
BufferedInputStream 和 BufferedOutputStream 属于字节缓冲流,强化了字节流 InputStream 和 OutputStream,关于字节流,我们前面已经详细地讲过了,可以戳这个链接去温习。
1)构造方法
BufferedInputStream(InputStream in):创建一个新的缓冲输入流,注意参数类型为InputStream。BufferedOutputStream(OutputStream out): 创建一个新的缓冲输出流,注意参数类型为OutputStream。
代码示例如下:
1 | // 创建字节缓冲输入流,先声明字节流 |
2)缓冲流的高效
我们通过复制一个 370M+ 的大文件,来测试缓冲流的效率。为了做对比,我们先用基本流来实现一下,代码如下:
1 | // 记录开始时间 |
不好意思,我本机比较菜,10 分钟还在复制中。切换到缓冲流试一下,代码如下:
1 | // 记录开始时间 |
只需要 8016 毫秒,如何更快呢?
可以换数组的方式来读写,这个我们前面也有讲到,代码如下:
1 | // 记录开始时间 |
这下就更快了,只需要 521 毫秒。
3)为什么字节缓冲流会这么快?
传统的 Java IO 是阻塞模式的,它的工作状态就是“读/写,等待,读/写,等待。。。。。。”
字节缓冲流解决的就是这个问题:一次多读点多写点,减少读写的频率,用空间换时间。
- 减少系统调用次数:在使用字节缓冲流时,数据不是立即写入磁盘或输出流,而是先写入缓冲区,当缓冲区满时再一次性写入磁盘或输出流。这样可以减少系统调用的次数,从而提高 I/O 操作的效率。
- 减少磁盘读写次数:在使用字节缓冲流时,当需要读取数据时,缓冲流会先从缓冲区中读取数据,如果缓冲区中没有足够的数据,则会一次性从磁盘或输入流中读取一定量的数据。同样地,当需要写入数据时,缓冲流会先将数据写入缓冲区,如果缓冲区满了,则会一次性将缓冲区中的数据写入磁盘或输出流。这样可以减少磁盘读写的次数,从而提高 I/O 操作的效率。
- 提高数据传输效率:在使用字节缓冲流时,由于数据是以块的形式进行传输,因此可以减少数据传输的次数,从而提高数据传输的效率。
我们来看 BufferedInputStream 的 read 方法:
1 | public synchronized int read() throws IOException { |
这段代码主要有两部分:
fill():该方法会将缓冲 buf 填满。getBufIfOpen()[pos++] & 0xff:返回当前读取位置 pos 处的字节(getBufIfOpen()返回的是 buffer 数组,是 byte 类型),并将其与 0xff 进行位与运算。这里的目的是将读取到的字节 b 当做无符号的字节处理,因为 Java 的 byte 类型是有符号的,而将 b 与 0xff 进行位与运算,就可以将其转换为无符号的字节,其范围为 0 到 255。
byte & 0xFF 我们一会再细讲。
再来看 FileInputStream 的 read 方法:
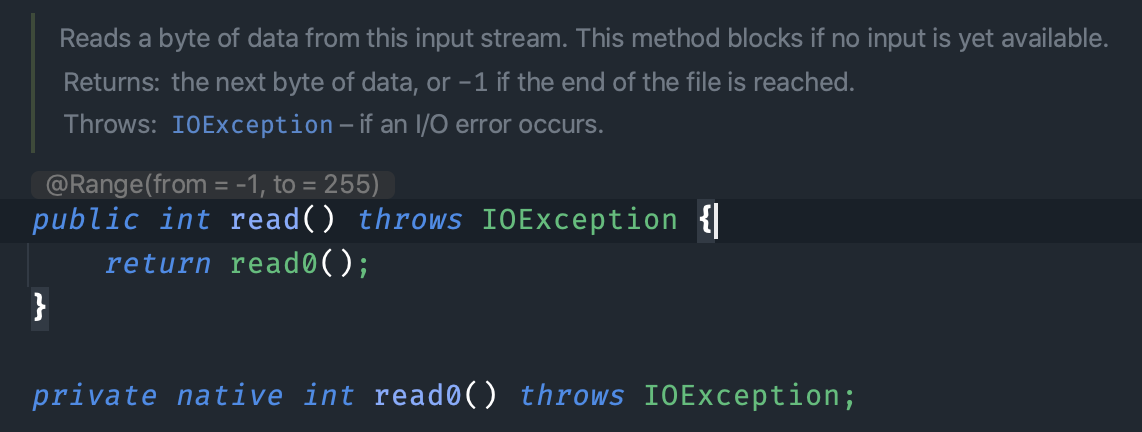
在这段代码中,read0() 方法是一个本地方法,它的实现是由底层操作系统提供的,并不是 Java 语言实现的。在不同的操作系统上,read0() 方法的实现可能会有所不同,但是它们的功能都是相同的,都是用于读取一个字节。
再来看一下 BufferedOutputStream 的 write(byte b[], int off, int len) 方法:
1 | public synchronized void write(byte b[], int off, int len) throws IOException { |
首先,该方法会检查写入的字节数是否大于等于缓冲区长度,如果是,则先将缓冲区中的数据刷新到磁盘中,然后直接将数据写入输出流。这样做是为了避免缓冲流级联时的问题,即缓冲区的大小不足以容纳写入的数据时,可能会引发级联刷新,导致效率降低。
级联问题(Cascade Problem)是指在一组缓冲流(Buffered Stream)中,由于缓冲区的大小不足以容纳要写入的数据,导致数据被分割成多个部分,并分别写入到不同的缓冲区中,最终需要逐个刷新缓冲区,从而导致性能下降的问题。
其次,如果写入的字节数小于缓冲区长度,则检查缓冲区中剩余的空间是否足够容纳要写入的字节数,如果不够,则先将缓冲区中的数据刷新到磁盘中。然后,使用 System.arraycopy() 方法将要写入的数据拷贝到缓冲区中,并更新计数器 count。
最后,如果写入的字节数小于缓冲区长度且缓冲区中还有剩余空间,则直接将要写入的数据拷贝到缓冲区中,并更新计数器 count。
也就是说,只有当 buf 写满了,才会 flush,将数据刷到磁盘,默认一次刷 8192 个字节。
1 | public BufferedOutputStream(OutputStream out) { |
如果 buf 没有写满,会继续写 buf。
对比一下 FileOutputStream 的 write 方法,同样是本地方法,一次只能写入一个字节。
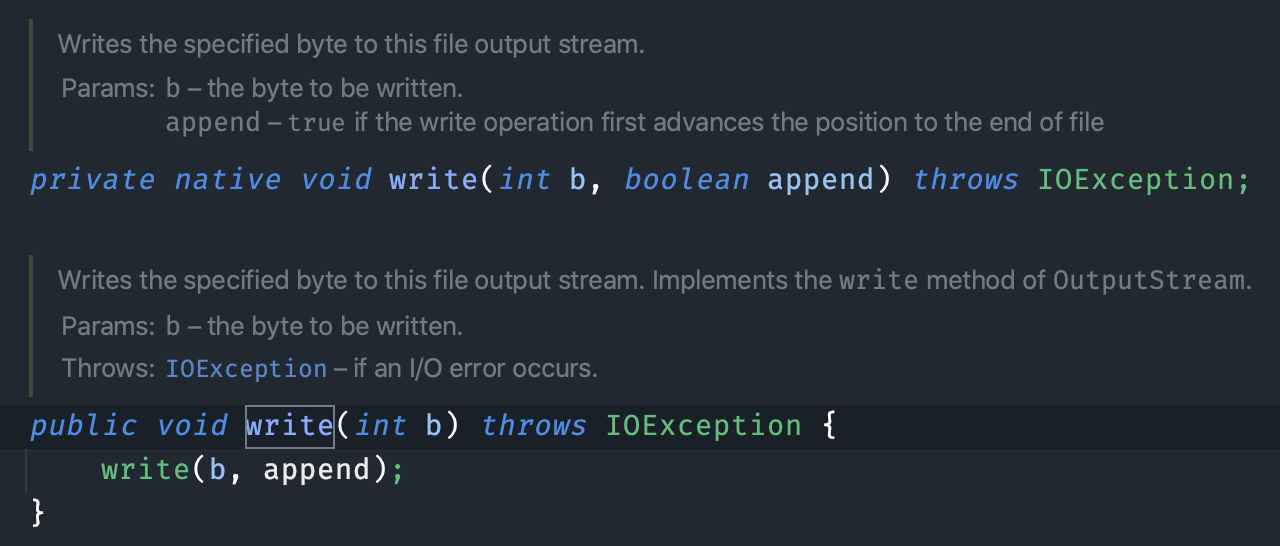
当把 BufferedOutputStream 和 BufferedInputStream 配合起来使用后,就减少了大量的读写次数,尤其是 byte[] bytes = new byte[8*1024],就相当于缓冲区的空间有 8 个 1024 字节,那读写效率就会大大提高。
4)byte & 0xFF
byte 类型通常被用于存储二进制数据,例如读取和写入文件、网络传输等场景。在这些场景下,byte 类型的变量可以用来存储数据流中的每个字节,从而进行读取和写入操作。
byte 类型是有符号的,即其取值范围为 -128 到 127。如果我们希望得到的是一个无符号的 byte 值,就需要使用 byte & 0xFF 来进行转换。
这是因为 0xFF 是一个无符号的整数,它的二进制表示为 11111111。当一个 byte 类型的值与 0xFF 进行位与运算时,会将 byte 类型的值转换为一个无符号的整数,其范围为 0 到 255。
0xff 是一个十六进制的数,相当于二进制的 11111111,& 运算符的意思是:如果两个操作数的对应位为 1,则输出 1,否则为 0;由于 0xff 有 8 个 1,单个 byte 转成 int 其实就是将 byte 和 int 类型的 255 进行(&)与运算。
例如,如果我们有一个 byte 类型的变量 b,其值为 -1,那么 b & 0xFF 的结果就是 255。这样就可以将一个有符号的 byte 类型的值转换为一个无符号的整数。
& 运算是一种二进制数据的计算方式, 两个操作位都为1,结果才为1,否则结果为0. 在上面的 getBufIfOpen()[pos++] & 0xff 计算过程中, byte 有 8bit, OXFF 是16进制的255, 表示的是 int 类型, int 有 32bit.
如果 getBufIfOpen()[pos++] 为 -118, 那么其原码表示为
1 | 00000000 00000000 00000000 10001010 |
反码为
1 | 11111111 11111111 11111111 11110101 |
补码为
1 | 11111111 11111111 11111111 11110110 |
0XFF 表示16进制的数据255, 原码, 反码, 补码都是一样的, 其二进制数据为
1 | 00000000 00000000 00000000 11111111 |
0XFF 和 -118 进行&运算后结果为
1 | 00000000 00000000 00000000 11110110 |
还原为原码后为
1 | 00000000 00000000 00000000 10001010 |
其表示的 int 值为 138,可见将 byte 类型的 -118 与 0XFF 进行与运算后值由 -118 变成了 int 类型的 138,其中低8位和byte的-118完全一致。
顺带聊一下 原码、反码和补码。
①、原码
原码就是符号位加上真值的绝对值,即用第一位表示符号,其余位表示值。比如如果是8位二进制:
1 | [+1]原 = 0000 0001 |
第一位是符号位。因为第一位是符号位,所以8位二进制数的取值范围就是:
1 | [1111 1111 , 0111 1111] |
即
1 | [-127 , 127] |
②、反码
反码的表示方法是:
- 正数的反码是其本身
- 负数的反码是在其原码的基础上,符号位不变,其余各个位取反。
例如:
1 | [+1] = [00000001]原 = [00000001]反 |
可见如果一个反码表示的是负数,人脑无法直观的看出来它的数值。通常要将其转换成原码再计算。
③、补码
补码的表示方法是:
- 正数的补码就是其本身
- 负数的补码是在其原码的基础上,符号位不变,其余各位取反,最后+1。(即在反码的基础上+1)
1 | [+1] = [00000001]原 = [00000001]反 = [00000001]补 |
对于负数,补码表示方式也是人脑无法直观看出其数值的。通常也需要转换成原码在计算其数值。
从上面可以看到:
- 对于正数:原码,反码,补码都是一样的
- 对于负数:原码,反码,补码都是不一样的
02、字符缓冲流
BufferedReader 类继承自 Reader 类,提供了一些便捷的方法,例如 readLine() 方法可以一次读取一行数据,而不是一个字符一个字符地读取。
BufferedWriter 类继承自 Writer 类,提供了一些便捷的方法,例如 newLine() 方法可以写入一个系统特定的行分隔符。
1)构造方法
BufferedReader(Reader in):创建一个新的缓冲输入流,注意参数类型为Reader。BufferedWriter(Writer out): 创建一个新的缓冲输出流,注意参数类型为Writer。
代码示例如下:
1 | // 创建字符缓冲输入流 |
2)字符缓冲流特有方法
字符缓冲流的基本方法与普通字符流调用方式一致,这里不再赘述,我们来看字符缓冲流特有的方法。
- BufferedReader:
String readLine(): 读一行数据,读取到最后返回 null - BufferedWriter:
newLine(): 换行,由系统定义换行符。
来看 readLine()方法的代码示例:
1 | // 创建流对象 |
再来看 newLine() 方法的代码示例:
1 | // 创建流对象 |
03、字符缓冲流练习
来欣赏一下我写的这篇诗:
6.岑夫子,丹丘生,将进酒,杯莫停。
1.君不见黄河之水天上来,奔流到海不复回。
8.钟鼓馔玉不足贵,但愿长醉不愿醒。
3.人生得意须尽欢,莫使金樽空对月。
5.烹羊宰牛且为乐,会须一饮三百杯。
2.君不见高堂明镜悲白发,朝如青丝暮成雪。
7.与君歌一曲,请君为我倾耳听。
4.天生我材必有用,千金散尽还复来。
如何才能按照正确的顺序来呢?
1 | // 创建map集合,保存文本数据,键为序号,值为文字 |
Java转换流
转换流可以将一个字节流包装成字符流,或者将一个字符流包装成字节流。这种转换通常用于处理文本数据,如读取文本文件或将数据从网络传输到应用程序。
01、编码和解码
在计算机中,数据通常以二进制形式存储和传输。
- 编码就是将原始数据(比如说文本、图像、视频、音频等)转换为二进制形式。
- 解码就是将二进制数据转换为原始数据,是一个反向的过程。
1 | String str = "沉默王二"; |
在这个示例中,首先定义了一个字符串变量 str 和一个字符集名称 charsetName。然后,使用 Charset.forName() 方法获取指定字符集的 Charset 对象。接着,使用字符串的 getBytes() 方法将字符串编码为指定字符集的字节数组。最后,使用 new String() 方法将字节数组解码为字符串。
02、字符集
Charset:字符集,是一组字符的集合,每个字符都有一个唯一的编码值,也称为码点。
常见的字符集包括 ASCII、Unicode 和 GBK,而 Unicode 字符集包含了多种编码方式,比如说 UTF-8、UTF-16。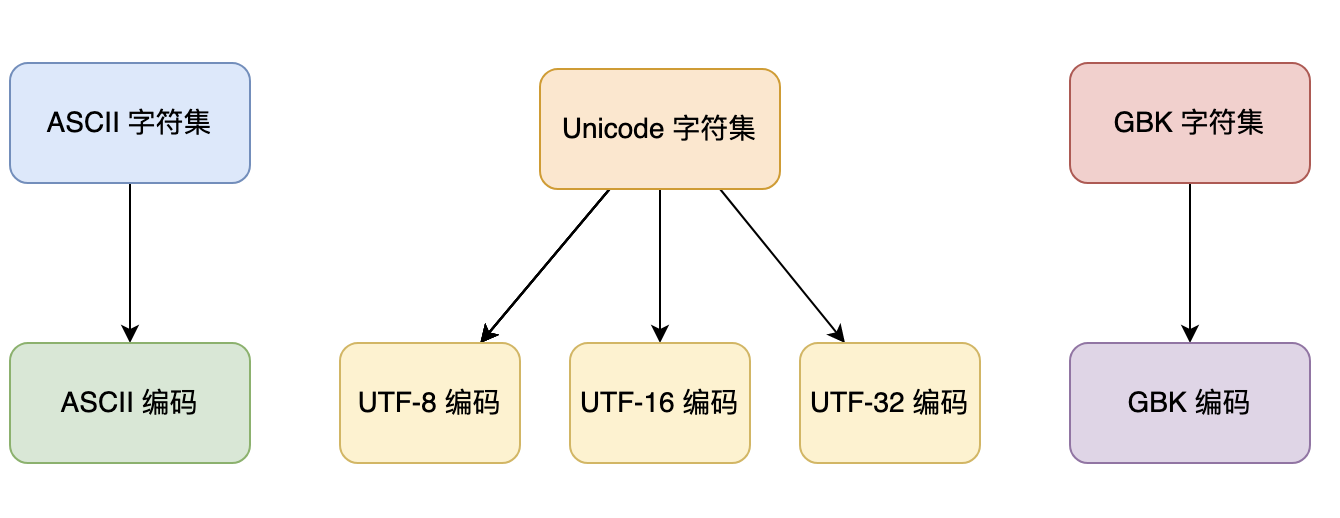
ASCII 字符集
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)字符集是一种最早的字符集,包含 128 个字符,其中包括控制字符、数字、英文字母以及一些标点符号。ASCII 字符集中的每个字符都有一个唯一的 7 位二进制编码(由 0 和 1 组成),可以表示为十进制数或十六进制数。
ASCII 编码方式是一种固定长度的编码方式,每个字符都使用 7 位二进制编码来表示。ASCII 编码只能表示英文字母、数字和少量的符号,不能表示其他语言的文字和符号,因此在全球范围内的应用受到了很大的限制。
Unicode 字符集
Unicode 包含了世界上几乎所有的字符,用于表示人类语言、符号和表情等各种信息。Unicode 字符集中的每个字符都有一个唯一的码点(code point),用于表示该字符在字符集中的位置,可以用十六进制数表示。
为了在计算机中存储和传输 Unicode 字符集中的字符,需要使用一种编码方式。UTF-8、UTF-16 和 UTF-32 都是 Unicode 字符集的编码方式,用于将 Unicode 字符集中的字符转换成字节序列,以便于存储和传输。它们的差别在于使用的字节长度不同。
- UTF-8 是一种可变长度的编码方式,对于 ASCII 字符(码点范围为
0x00~0x7F),使用一个字节表示,对于其他 Unicode 字符,使用两个、三个或四个字节表示。UTF-8 编码方式被广泛应用于互联网和计算机领域,因为它可以有效地压缩数据,适用于网络传输和存储。 - UTF-16 是一种固定长度的编码方式,对于基本多语言平面(Basic Multilingual Plane,Unicode 字符集中的一个码位范围,包含了世界上大部分常用的字符,总共包含了超过 65,000 个码位)中的字符(码点范围为
0x0000~0xFFFF),使用两个字节表示,对于其他 Unicode 字符,使用四个字节表示。 - UTF-32 是一种固定长度的编码方式,对于所有 Unicode 字符,使用四个字节表示。
GBK 字符集
GBK 包含了 GB2312 字符集中的字符,同时还扩展了许多其他汉字字符和符号,共收录了 21,913 个字符。GBK 采用双字节编码方式,每个汉字占用 2 个字节,其中高字节和低字节都使用了 8 位,因此 GBK 编码共有 2^16=65536 种可能的编码,其中大部分被用于表示汉字字符。
GBK 编码是一种变长的编码方式,对于 ASCII 字符(码位范围为 0x00 到 0x7F),使用一个字节表示,对于其他字符,使用两个字节表示。GBK 编码中的每个字节都可以采用 0x81 到 0xFE 之间的任意一个值,因此可以表示 2^15=32768 个字符。为了避免与 ASCII 码冲突,GBK 编码的第一个字节采用了 0x81 到 0xFE 之间除了 0x7F 的所有值,第二个字节采用了 0x40 到 0x7E 和 0x80 到 0xFE 之间的所有值,共 94 个值。
GB2312 的全名是《信息交换用汉字编码字符集基本集》,也被称为“国标码”。采用了双字节编码方式,每个汉字占用 2 个字节,其中高字节和低字节都使用了 8 位,因此 GB2312 编码共有 2^16=65536 种可能的编码,其中大部分被用于表示汉字字符。GB2312 编码中的每个字节都可以采用 0xA1 到 0xF7 之间的任意一个值,因此可以表示 126 个字符。
GB2312 是一个较为简单的字符集,只包含了常用的汉字和符号,因此对于一些较为罕见的汉字和生僻字,GB2312 不能满足需求,现在已经逐渐被 GBK、GB18030 等字符集所取代。
GB18030 是最新的中文码表。收录汉字 70244 个,采用多字节编码,每个字可以由 1 个、2 个或 4 个字节组成。支持中国国内少数民族的文字,同时支持繁体汉字以及日韩汉字等。
03、乱码
当使用不同的编码方式读取或者写入文件时,就会出现乱码问题,来看示例。
1 | String s = "沉默王二!"; |
在上面的示例代码中,首先定义了一个包含中文字符的字符串,然后将该字符串按 GBK 编码方式保存到文件中,接着将文件按默认编码方式(UTF-8)读取,并显示内容。此时就会出现乱码问题,显示为“��Ĭ������”。
这是因为文件中的 GBK 编码的字符在使用 UTF-8 编码方式解析时无法正确解析,从而导致出现乱码问题。
那如何才能解决乱码问题呢?
这就引出我们今天的主角了——转换流。
04、InputStreamReader
java.io.InputStreamReader 是 Reader 类的子类。它的作用是将字节流(InputStream)转换为字符流(Reader),同时支持指定的字符集编码方式,从而实现字符流与字节流之间的转换。
1)构造方法
InputStreamReader(InputStream in): 创建一个使用默认字符集的字符流。InputStreamReader(InputStream in, String charsetName): 创建一个指定字符集的字符流。
代码示例如下:
1 | InputStreamReader isr = new InputStreamReader(new FileInputStream("in.txt")); |
2)解决编码问题
下面是一个使用 InputStreamReader 解决乱码问题的示例代码:
1 | String s = "沉默王二!"; |
由于使用了 InputStreamReader 对字节流进行了编码方式的转换,因此在读取字符流时就可以正确地解析出中文字符,避免了乱码问题。
05、OutputStreamWriter
java.io.OutputStreamWriter 是 Writer 的子类,字面看容易误以为是转为字符流,其实是将字符流转换为字节流,是字符流到字节流的桥梁。
OutputStreamWriter(OutputStream in): 创建一个使用默认字符集的字符流。OutputStreamWriter(OutputStream in, String charsetName):创建一个指定字符集的字符流。
代码示例如下:
1 | OutputStreamWriter isr = new OutputStreamWriter(new FileOutputStream("a.txt")); |
通常为了提高读写效率,我们会在转换流上再加一层缓冲流,来看代码示例:
1 | try { |
在上面的示例代码中,首先使用 FileInputStream 从文件中读取字节流,使用 UTF-8 编码方式进行读取。然后,使用 InputStreamReader 将字节流转换为字符流,使用 UTF-8 编码方式进行转换。接着,使用 BufferedReader 包装字符流,提高读取效率。然后,创建 FileOutputStream 用于输出文件,使用 UTF-8 编码方式进行创建。接着,使用 OutputStreamWriter 将输出流转换为字符流,使用 UTF-8 编码方式进行转换。最后,使用 BufferedWriter 包装转换流,提高写入效率。
06、小结
InputStreamReader 和 OutputStreamWriter 是将字节流转换为字符流或者将字符流转换为字节流。通常用于解决字节流和字符流之间的转换问题,可以将字节流以指定的字符集编码方式转换为字符流,或者将字符流以指定的字符集编码方式转换为字节流。
InputStreamReader 类的常用方法包括:
read():从输入流中读取一个字符的数据。read(char[] cbuf, int off, int len):从输入流中读取 len 个字符的数据到指定的字符数组 cbuf 中,从 off 位置开始存放。ready():返回此流是否已准备好读取。close():关闭输入流。
OutputStreamWriter 类的常用方法包括:
write(int c):向输出流中写入一个字符的数据。write(char[] cbuf, int off, int len):向输出流中写入指定字符数组 cbuf 中的 len 个字符,从 off 位置开始。flush():将缓冲区的数据写入输出流中。close():关闭输出流。
在使用转换流时,需要指定正确的字符集编码方式,否则可能会导致数据读取或写入出现乱码。
Java序列流
Java 的序列流(ObjectInputStream 和 ObjectOutputStream)是一种可以将 Java 对象序列化和反序列化的流。
01、ObjectOutputStream
java.io.ObjectOutputStream 继承自 OutputStream 类,因此可以将序列化后的字节序列写入到文件、网络等输出流中。
来看 ObjectOutputStream 的构造方法:ObjectOutputStream(OutputStream out)
该构造方法接收一个 OutputStream 对象作为参数,用于将序列化后的字节序列输出到指定的输出流中。例如:
1 | FileOutputStream fos = new FileOutputStream("file.txt"); |
一个对象要想序列化,必须满足两个条件:
- 该类必须实现
java.io.Serializable接口,否则会抛出NotSerializableException。 - 该类的所有字段都必须是可序列化的。如果一个字段不需要序列化,则需要使用
transient关键字进行修饰。static 和 transient 修饰的字段是不会被序列化的。
使用示例如下:
1 | public class Employee implements Serializable { |
接下来,来聊聊 writeObject (Object obj) 方法,该方法是 ObjectOutputStream 类中用于将对象序列化成字节序列并输出到输出流中的方法,可以处理对象之间的引用关系、继承关系、静态字段和 transient 字段。
1 | public class ObjectOutputStreamDemo { |
上面的代码中,首先创建了一个 Person 对象,然后使用 FileOutputStream 和 ObjectOutputStream 将 Person 对象序列化并输出到 person.dat 文件中。在 Person 类中,实现了 Serializable 接口,表示该类可以进行对象序列化。
02、ObjectInputStream
ObjectInputStream 可以读取 ObjectOutputStream 写入的字节流,并将其反序列化为相应的对象(包含对象的数据、对象的类型和对象中存储的属性等信息)。
说简单点就是,序列化之前是什么样子,反序列化后就是什么样子。
来看一下构造方法:ObjectInputStream(InputStream in) : 创建一个指定 InputStream 的 ObjectInputStream。
其中,ObjectInputStream 的 readObject 方法用来读取指定文件中的对象,示例如下:
1 | String filename = "logs/person.dat"; // 待反序列化的文件名 |
03、Kryo
实际开发中,很少使用 JDK 自带的序列化和反序列化,这是因为:
- 可移植性差:Java 特有的,无法跨语言进行序列化和反序列化。
- 性能差:序列化后的字节体积大,增加了传输/保存成本。
- 安全问题:攻击者可以通过构造恶意数据来实现远程代码执行,从而对系统造成严重的安全威胁。相关阅读:Java 反序列化漏洞之殇 。
Kryo 是一个优秀的 Java 序列化和反序列化库,具有高性能、高效率和易于使用和扩展等特点,有效地解决了 JDK 自带的序列化机制的痛点。
GitHub 地址:https://github.com/EsotericSoftware/kryo
使用示例:
第一步,在 pom.xml 中引入依赖。
1 | <!-- 引入 Kryo 序列化工具 --> |
第二步,创建一个 Kryo 对象,并使用 register() 方法将对象进行注册。然后,使用 writeObject() 方法将 Java 对象序列化为二进制流,再使用 readObject() 方法将二进制流反序列化为 Java 对象。最后,输出反序列化后的 Java 对象。
1 | public class KryoDemo { |
打印流
System.out.println() 的使用频率恐怕不亚于 main 方法的使用频率。其中 System.out 返回的正是打印流 PrintStream 。
除此之外,还有它还有一个孪生兄弟,PrintWriter。PrintStream 是 OutputStream 的子类,PrintWriter 是 Writer 的子类,也就是说,一个字节流,一个是字符流。
打印流具有以下几个特点:
- 可以自动进行数据类型转换:打印流可以将各种数据类型转换为字符串,并输出到指定的输出流中。
- 可以自动进行换行操作:打印流可以在输出字符串的末尾自动添加换行符,方便输出多个字符串时的格式控制。
- 可以输出到控制台或者文件中:打印流可以将数据输出到控制台或者文件中,方便调试和日志记录(尽管生产环境下更推荐使用 Logback、ELK 等)。
PrintStream 类的常用方法包括:
print():输出一个对象的字符串表示形式。println():输出一个对象的字符串表示形式,并在末尾添加一个换行符。printf():使用指定的格式字符串和参数输出格式化的字符串。
1 | PrintStream ps = System.out; |
在这个示例中,我们创建了一个 PrintStream 对象 ps,它输出到控制台。我们使用 ps 的 print 和 println 方法输出了一些字符串。
使用 printf 方法输出了一个格式化字符串,其中 %s、%d 和 %.2f 分别表示字符串、整数和浮点数的格式化输出。我们使用逗号分隔的参数列表指定了要输出的值。
来详细说说 printf 方法哈。
1 | public PrintStream printf(String format, Object... args); |
其中,format 参数是格式化字符串,args 参数是要输出的参数列表。格式化字符串包含了普通字符和转换说明符。普通字符是指除了转换说明符之外的字符,它们在输出时直接输出。转换说明符是由百分号(%)和一个或多个字符组成的,用于指定输出的格式和数据类型。
下面是 Java 的常用转换说明符及对应的输出格式:
%s:输出一个字符串。%d或%i:输出一个十进制整数。%x或%X:输出一个十六进制整数,%x输出小写字母,%X输出大写字母。%f或%F:输出一个浮点数。%e或%E:输出一个科学计数法表示的浮点数,%e输出小写字母 e,%E输出大写字母 E。%g或%G:输出一个浮点数,自动选择%f或%e/%E格式输出。%c:输出一个字符。%b:输出一个布尔值。%h:输出一个哈希码(16进制)。%n:换行符。
除了转换说明符之外,Java 的 printf 方法还支持一些修饰符,用于指定输出的宽度、精度、对齐方式等。
- 宽度修饰符:用数字指定输出的最小宽度,如果输出的数据不足指定宽度,则在左侧或右侧填充空格或零。
- 精度修饰符:用点号(.)和数字指定浮点数或字符串的精度,对于浮点数,指定小数点后的位数,对于字符串,指定输出的字符数。
- 对齐修饰符:用减号(-)或零号(0)指定输出的对齐方式,减号表示左对齐,零号表示右对齐并填充零。
下面是一些示例:
1 | int num = 123; |
具体来说,
- 我们使用
%5d来指定输出的整数占据 5 个字符的宽度,不足部分在左侧填充空格。 - 使用
%-5d来指定输出的整数占据 5 个字符的宽度,不足部分在右侧填充空格。 - 使用
%05d来指定输出的整数占据 5 个字符的宽度,不足部分在左侧填充 0。 - 使用
%10.2f来指定输出的浮点数占据 10 个字符的宽度,保留 2 位小数,不足部分在左侧填充空格。 - 使用
%-10.4f来指定输出的浮点数占据 10 个字符的宽度,保留 4 位小数,不足部分在右侧填充空格。 - 使用
%10s来指定输出的字符串占据 10 个字符的宽度,不足部分在左侧填充空格。 - 使用
%-10s来指定输出的字符串占据 10 个字符的宽度,不足部分在右侧填充空格。
接下来,我们给出一个 PrintWriter 的示例:
1 | PrintWriter writer = new PrintWriter(new FileWriter("output.txt")); |
首先,我们创建一个 PrintWriter 对象,它的构造函数接收一个 Writer 对象作为参数。在这里,我们使用 FileWriter 来创建一个输出文件流,并将其作为参数传递给 PrintWriter 的构造函数。然后,我们使用 PrintWriter 的 println 和 printf 方法来输出两行内容,其中 printf 方法可以接收格式化字符串。最后,我们调用 PrintWriter 的 close 方法来关闭输出流。
我们也可以不创建 FileWriter 对象,直接指定文件名。
1 | PrintWriter pw = new PrintWriter("output.txt"); |