这篇文章写的很好:WAF入门扫盲篇(一遍就懂)
https://habr.com/en/companies/dsec/articles/454592/
引言&&介绍WAF
早就想整理有关waf相关的内容了,今天系统梳理下
WAF的部署模式
如果WAF像传统防火墙那样,放置在网络入口,那么,对于DDOS攻击来说,它是很容易沦陷的。所以WAF一般是部署在防火墙(特别是高防DDOS设备)后面,基本架构如下图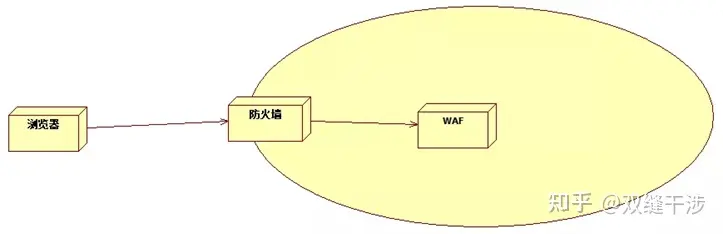
由于性能差异这么大,所以WAF和防火墙之间还会部署负载均衡设备。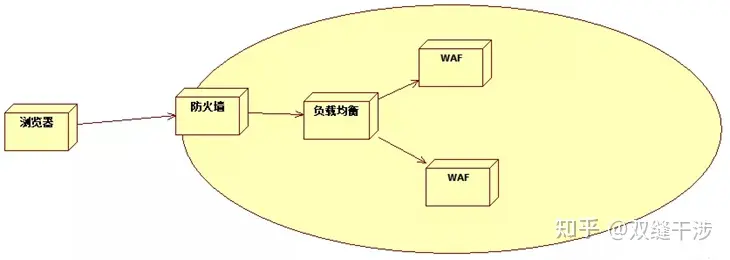
| 部署方式 | 工作原理 | 优点 | 缺点 |
|---|---|---|---|
| 透明模式 | 工作模式为透明桥模式,检测、过滤或转发两者之间的会话,客户端直接访问Web服务器,感知不到WAF存在。 | 配置简单,不改变原有网络环境,通过硬件Bypass功能不影响网络原有业务通讯 | Bypass功能启动后WAF自身功能失效,网络所有流量都经过WAF,对设备硬件性能要求高 |
| 路由代理模式 | 工作模式为路由转发模式,需要配置WAF的转发接口IP地址以及路由,其它和透明模式一样。 | 配置相对简单,不改变原有网络环境 | 存在单点故障问题,负责转发所有流量 |
| 反向代理模式 | 工作原理是将Web服务器的地址映射到反向代理服务器上,客户端实际访问的是WAF,由WAF来转发请求和响应。 | 能够支持负载均衡 | 配置较为复杂,需要改变原有网络环境 |
| 旁路模式 | 工作模式为旁听模式,将交换机端口上的HTTP流量镜像到WAF,WAF对HTTP流量进行监控和报警。 | 不改变原有网络环境,对原有网络不会有影响 | 只进行监控和报警,不进行阻断,达不到Web防护功能 |
WAF工作模式
关闭模式:可随时关闭,不影响整个业务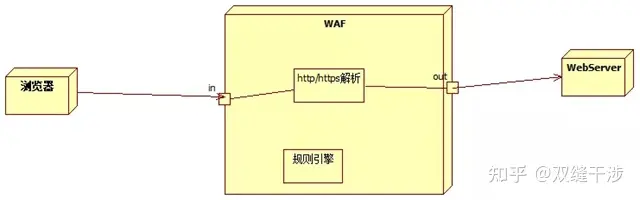
WAF的监听模式是既过规则,也会直接传递给web服务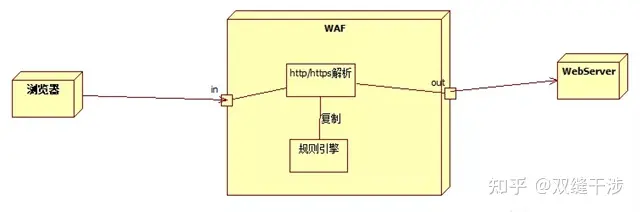
WAF的防护模式是直接过规则,不会直接传递给web服务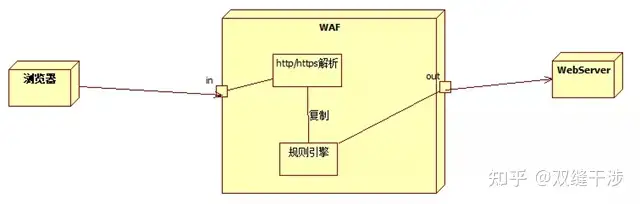
规则引擎原理
- 请求部分
- 网络层
- 白名单:很多时候部署在WAF后面的应用,需要测试接口对非法输入的处理,但又不想关闭对该站点的监控,为了防止WAF对测试活动的影响,对来源IP和目标IP设置白名单,绕过WAF的拦截。从性能角度来考虑,白名单过滤功能是不可能放在其它过滤功能后面,那么它应该是规则引擎在网络层过滤的第一步。
- 黑名单:同样,对于已知有害的来源IP,是越早拦截越好,出于性能考虑,黑名单拦截功能应该在网络层,那么它应该紧跟在白名单后面。
- 应用层
- https拆解:随着https越来越普及,WAF需要对https请求和响应进行检测和过滤,所以,WAF必须支持使用证书对https内容进行拆解。
- http方法防护:不少http方法是有安全风险的,如果webserver的配置有问题,如果不在这一步拦截掉,而url白名单的来源IP又可能被攻击,那么就可以存在站点沦陷的风险。一般是拦截除了HEAD,GET,POST之外的方法
- url白名单:由于某些接口(如请求某些静态资源)并不会存在漏洞,没必要对这些url进行规则过滤,或者防护站点某些url接口有所更新,需要特定的来源IP进行测试。应当存在url和来源IP对应的白名单
- url黑名单:同样由于某些接口的实现可能会涉及大量运算,可能需要对该url访问进行次数限制,需要存在一个url和次数的黑名单。
- http请求解码:http请求很多时候对头部和内容的数据往往会进行编码,如url编码,html编码,js编码,十六制编码,base64编码,主要是为了传输一些二进制数据,或攻击者用于绕过各种防护设备。只有对数据进行解码,才能够知道它真实的payload。所以需要对http请求进行解码。
- http请求头部过规则:GET,HEAD方法的参数都是紧跟URL,这个阶段就可以进行过滤,而且先对请求头部过滤,也是基于性能考虑。毕竟请求url参数和头部都是key-value方式,解析相对比内容要快。
- http请求内容过规则:POST方法的参数基本都是放在请求内容里。
- 网络层
- 响应部分
- 响应头部过规则:响应头部有不少字段会泄露背后服务的关键信息,如server会泄露webserver软件及版本,x-powered-by会泄露cgi语言和版本(PHP,Python,Perl,Ruby之类),Via和Max-Forward会泄露WebServer的拓扑。为了避免攻击者利用这些信息攻击,需要对响应头部某些字段进行屏蔽或伪装。
- 响应内容过规则:这一部分也叫做软补丁功能。为什么呢?如果webserver的应用服务抛异常了,并把异常信息显示在页面,这是一种常见的信息泄露。如果需要研发团队来修改和测试,运维团队对该服务进行打补丁上线,整个过程可能持续几周,存在很大的风险窗口。如果在WAF上,对这些信息进行伪装或屏蔽,就可以极大降低安全风险。更加不用那些会泄露用户信息,金融信息等服务。
WAF动作
WAF每条规则都会配置动作,对命中规则的请求进行对应的处理。每个WAF产品对动作定义不大一样。
- ModSecurity定义了allow, block, deny, drop, pass, pause, proxy, redirect
- allow: 命中了某条规则后,不需要对请求/响应应用其它规则,直接让请求通过。这个可以用于白名单。
- block: 并不是一个真正的动作,它的行为取决于配置的默认动作,如果默认动作更新,使用block的规则行为也随即改变。在安全响应方面,它可用于批量进行规则作为更新。
- deny: 中断规则处理,拦截请求/响应。在客户端的角度来说,这个动作会返回4xx或5xx的状态码(取决于规则定义status),但并没有中断当前的连接
- drop: 对当前tcp连接进行关闭操作,它和deny的不同是:deny之后,客户端仍然可以提交请求,但使用drop后,客户端只有重新连接才可以访问。这个动作可以节省后端服务的连接数
- pass: 命中某条规则继续匹配下一条规则。可用于对请求进行精细地过滤,但会对响应速度有较大影响。
- pause: 命中某条规则,对当前事务暂停指定的毫秒。一般用于防止登录爆破。如果遭受DDOS攻击,会恶化整个web服务的响应速度
- proxy: 把命中规则的请求转发到另外一个web服务去。这个功能类似反向代理。由于它对客户端完全来说,完全是无感知,可以用它导向请求到蜜罐系统。这个动作是一个非常优秀的动作。
- redirect: 当规则被命中,它会返回一个重定向,指示浏览器访问另外一个url。它和proxy的区别是,它对客户端是感知。可用于配置新上线接口或屏蔽某些有问题的接口。
- Naxsi定义了accept, block, drop
- accept: 对应ModSecurity的allow, 一旦命中立马放行
- block: 对应ModSecurity的deny
- drop: 对应ModSecurity的drop
- 华为云WAF定义了allow, deny, redirect
- accept: 对应ModSecurity的allow, 一旦命中立马放行
- deny: 对应ModSecurity的deny, 默认返回418
- redirect: 对应Modsecurity的redirect
- openrestyl lua WAF定义了allow, deny,drop, redirect
- accept: 对应ModSecurity的allow, 一旦命中立马放行
- deny: 对应ModSecurity的deny, 默认返回403
- drop: 对应ModSecurity的drop
- redirect: 对应Modsecurity的redirect
对于动作配置方面,有这样的建议:
在功能开发方面,drop最好能够先返回一个状态码再停止掉整个连接,drop, deny状态码尽量可以通过规则配置。
在配置规则时,对于drop, deny的状态码,每条规则或规则组都返回不同的状态码。
这样做的好处是:
有效隐藏WAF的特征,让攻击者无法确认是否有WAF存在
当出现规则误拦截时,可以根据返回码快速定位是哪条规则误拦截。这是从无数次背锅感悟出来的血的教训
WAF规则与报表
本上,WAF处理http分为四个阶段:请求头部,请求内容,响应头部,响应内容。那么WAF规则就是,定义在某个阶段WAF对符合某种条件的http请求执行指定动作的条例。根据这个,WAF规则必须要包含这些元素:过滤条件,阶段,动作。由于http消息在传输过程中会对数据进行某种编码,所以,WAF规则往往也需要定义解码器。同时为了审计作用,WAF规则往往定义id,是否对结果记录,以及字段抽取,命中规则的严重级别所以,一条WAF规则往往包含:id, 解码器,过滤条件,阶段,动作和日志格式,严重级别。
以一条ModSecurity规则为例:
SecRule REQUEST_FILENAME|ARGS_NAMES|ARGS|XML:/* “\bsys.user_catalog\b” \ “phase:2,rev:’2.1.3’,capture,t:none,t:urlDecodeUni,t:htmlEntityDecode,t:lowercase,t:replaceComments,t:compressWhiteSpace,ctl:auditLogParts=+E, \ block,msg:’Blind SQL Injection Attack’,id:’959517’,tag:’WEB_ATTACK/SQL_INJECTION’,tag:’WASCTC/WASC-19’,tag:’OWASP_TOP_10/A1’,tag:’OWASP_AppSensor/CIE1’, \ tag:’PCI/6.5.2’,logdata:’%{TX.0}’,severity:’2’,setvar:’tx.msg=%{rule.msg}’,setvar:tx.sql_injection_score=+%{tx.critical_anomaly_score}, \ setvar:tx.anomaly_score=+%{tx.critical_anomaly_score},setvar:tx.%{rule.id}-WEB_ATTACK/SQL_INJECTION-%{matched_var_name}=%{tx.0}”
看起来非常恐怖。翻译成XML就清晰多了
1 | <rule> |
规则陷阱:规则之间的关系非常复杂,特别过滤条件是使用正则表达式的,往往是会有包含关系,如[0-9]+包含了[1-2]+。那么,假设规则a先加入WAF,后面又新增了条规则b,在语法上,b的过滤条件包含了a,而且在配置上,不小心放在a前面,那么,就会出现误判的情况。
误判和漏判,是很常见的问题。但在严重程度上,却是不一样。
- 漏判,可能会造成恶意请求绕过WAF,跑到业务后台,但在业务后台加上其它安全措施,却可以缓解威胁。
- 误判,则是直接在WAF把正常请求给拦截掉,影响正常的业务。曾经某大厂重要业务部门上WAF,由于误判,导致正常交易只有50%成功,几上几下之后,WAF团队的人基本干掉了。
所以,在测试环境,WAF规则要越严格越好。但在生产环境,对有把握的规则才维持原样,其它规则尽量放宽松一些。
虽然WAF规则可以设置一个id用于追溯,这远远不够,因为无法追溯是由哪个消息触发,规则对消息处理的顺序是怎样。所以,一个稳妥的规则引擎,应当在http消息接收时,在头部增加一个消息id,当消息离开WAF前,删除掉这个消息id。通过这种方式,可以很好追溯到每条消息会触发哪些规则,触发结果是怎样。当出现误判情况下,也可以立马知道是哪些规则有问题,顺序是怎样,规则定义是否合理。
报表:
WAF报表除了是展示给用户看,还可以用于优化规则。如下面场景:
- 某些规则一直没有命中,配置起来只会浪费计算资源,影响用户体现。
- 某些规则虽然有命中,但命中率较低,应该是放置在后面,而命中率高的则应该调整在前面。
- 某些URL访问频率较高,且并非标准浏览器访问,需要进一步观察和分析,看是否会有漏判风险
那么,报表应该从哪些维度来展示呢?先从语义来描述一下http消息流经waf的过程:
- 客户端A在物理地点B,使用IP地址C访问站点D,向URL地址E发起方法为F的HTTP请求G,命中了解码器为H,类型为I,风险级别为J,执行动作为K的规则L。
- 站点M向IP地址N返回响应O,命中了解码器为P,类型为Q,风险级别为R,执行动作为S的规则T。
由语义来看,去重之后,报表的维度至少要包含:
- 客户端(user_agent)分布
- IP地址,甚至是IP段分布
- 物理地点分布
- 站点分布分布
- URL分布
- HTTP方法分布
- 请求分布(这个会比较困难,基于长度来看会比较好)
- 解码器分布
- 规则类型分布(一般是指针对的攻击类型)
- 风险级别分布
- 动作分布
- 规则ID分布
- 响应分布(和请求分布一样困难)
- 时间分布(任何事件只能在时间中进行)
- 总请求数
- 拦截数量
WAF检测原理
- 基于规则匹配:一般都是基于一定的正则语法进行匹配,例如匹配函数 concat(),而不会匹配字符 concat。而 MySQL里面concat函数调用的时候括号是可以被隔开的。例如concat (),就可以绕过该正则。
- 基于语义分析:将输入的参数模拟为真实语句去运行,然后判断结果是否有问题。这种理念类似于一个 webshell检测引擎,在不考虑性能等情况下,将PHP的Zend引擎下执行命令的函数hook住,如果该函数被调用,会先进入自己的逻辑去判断。如果符合恶意执行的逻辑则判断为webshell执行,从而实现webshell的识别。对于语义分析的WAF,绕过理念会更加复杂和困难。因为你不再是对正则进行绕过。而是类似于对一个解析引擎进行黑盒测试的绕过,将其绕过后还要保证后端的真实解析引擎不出错。类似于前面举例 concat的绕过,本质上是利用了前端语言引擎的解析和后端MySQL引擎解析的不一致达成绕过。而在基于语义分析绕过的情况下,再也无法使用等价替换的手段,只能通过WAF引擎与后端服务器引擎不一致来绕过。
- RASP技术:例如OPENRASP有个功能是拦截所有 php/jsp 等脚本文件的写入操作,从攻击会产生的行为去进行检测和防御,http://blog.nsfocus.net/rasp-tech/
攻击(红对)视角下的WAF
WAF的识别、检测、绕过原理与实战案例 https://www.freebuf.com/articles/web/336869.html
识别WAF
不同的waf有着不同的绕过策略,能够正确地识别waf很关键
一些开源项目:
- Awesome WAF 是一个 GitHub 上的开源项目,旨在为 Web 应用防火墙(WAF)领域提供一个全面的资源库。它汇集了大量的 WAF 相关信息:https://github.com/0xInfection/Awesome-WAF,相关资料:https://xz.aliyun.com/t/6422
- wafw00f:WAF指纹识别工具,https://github.com/EnableSecurity/wafw00f,相关资料:https://www.freebuf.com/articles/web/384115.html
除了这些指纹,还可以通过waf拦截页面来判断是什么waf:https://mp.weixin.qq.com/s/8F060FU9g_78z57UKS-JsQ
WAF绕过手法
干货 | 实战绕过WAF各种姿势总结:https://cloud.tencent.com/developer/article/1969001
WAF机制及绕过方法总结:注入篇:https://www.freebuf.com/articles/web/229982.html
https://rivers.chaitin.cn/blog/cqj7vdp0lnedo7thq0a0
https://xz.aliyun.com/t/15
从WAF的防范手段角度考虑,可以整理以下思路
- 基于IP封锁
- 基于http请求头封锁IP 可使用burp suite插件fake-ip进行绕过
- 基于TCP封锁IP 使用IP代理池不断切换真实IP
- 利用白名单,一些waf会设置一些白名单,比如针对360、百度等爬虫的白名单,可以通过设置特殊的请求头绕过
- 基于规则问题
- 常见规则类型:
- 正则表达式规则:匹配特定的字符序列。
- 模版匹配规则:匹配预定义的攻击模板。
- 行为分析规则:分析请求行为,如请求频率、参数变化等。
- 绕过方法:
- 编码绕过: 利用URL编码、HTML编码、Unicode编码等方式对恶意payload进行编码,绕过正则匹配。
- 大小写绕过: 许多WAF对大小写敏感,通过大小写混合的方式绕过规则。
- 注释绕过: 在payload中插入注释,干扰WAF的检测。
- 特殊字符绕过: 利用特殊字符(如空格、换行符)绕过WAF。
- 时间差攻击: 针对基于时间差的检测机制,通过多次请求,逐渐增加payload长度,最终绕过WAF。
- 常见规则类型:
- 基于解析差异
- 通过业务特性绕过 在某些业务中,一些字符会被替换成空(如很多利用json来传递数据的网站很多会把凡斜杠\替换成空,这种则可以利用burpsuit进行fuzzing查找被处理掉的字符),利用这个就可以用来绕过waf:’an\d‘’=‘会变成’and‘’=’,导致waf绕过.
1
2
3
4
5
6GET /index.php?id=’an\d''='
Host: localhost
Accept: */*
Accept-Language: en
User-Agent: Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0)
Connection: close - 特殊字符绕过,类似前面的内容
- Mutilpart变量覆盖绕过 有些waf检测filename这个属性存在的时候下面的内容则不进行sql注入检测,因此可以构造同名参数前面一个name包含filename这个属性,后面再加一个正常的name属性,但是apache解析的时候会解析后面那个name属性,从而导致waf绕过。
1
2
3
4
5
6
7
8
9
10
11
12
13
14POST /index.php
Host: localhost
Accept: */*
Accept-Language: en
User-Agent: Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0)
Connection: close
Content-Type: multipart/form-data; boundary=--------1099641188
Content-Length: 101
----------1099641188
Content-Disposition: form-data; name=“id;filename=xx”;name=“id”
'and''=‘
----------1099641188-- - WAF 解析与 Web 服务解析不一致部分 ASP+IIS 会转换 %u0065 格式的字符Apache 会解析畸形 Method:.php –> /1.php.dvw.123 从后往前解析,碰到php才会解析
- Iis5.0-6.0解析漏洞,xx.asp/xx.jpg ,xx.asp目录下的文件都解析成asp文件,xx.asp;.jpg 默认被解析为asp文件
- Iis7.5解析漏洞(php.ini开启fix_pathinfo),xx.jpg 我们在上传文件时,一句话木马写成xx.jpg,访问时后面加上xx.jpg/xx.php,图片文件会以php格式执行
- nginx解析漏洞(php.ini开启fix_pathinfo),xx.jpg%00.php Nginx <8.03 空字节代码执行漏洞,同一个参数多次出现, 取的位置不一样
- 通过业务特性绕过
- 基于资源的绕过
使用消耗大的载荷,耗尽WAF的计算资源,通过增加传递得参数数量,达到waf检测上限,超出的参数就可绕过waf了。比如waf检测文本内容为40字节,多出40的就不再检测,那我们可以把脚本文件写在40个字节文件之后。再比如我们通过缓冲区溢出绕过WAF:当我们上传到服务器的数据量大于waf可以检测的数据量时,可以通过发送大量的垃圾数据将 WAF 溢出,从而绕过waf。union select= and (select 1)=(select 0xA*111111111111) unIon selectand 1=1 = and 1=1 and 111111…11111111 - 基于架构的绕过
寻找真实ip绕过云waf,云waf通过配置NS或者CNAME记录,使得对网站的请求报文优先经过WAF主机,经过WAF主机过滤之后,将被认为无害的请求报文再送给实际的网站服务器进行请求,此时只要找到服务器的真实ip,修改host为服务器真是ip即可绕过云waf
常见寻找真实ip的方式有如下几种- 证书信息查询 https://myssl.com/
- dns历史解析记录
- 搜集子域名ip c段(考虑到费用问题,一些子域名并不会部署)
- 超级ping
- 寻找没有部署waf的nginx反代机器:当waf在nginx服务器上部署,且存在nginx集群时,可以试试尝试寻找能反代服务却又没用部署waf的机器访问进行绕过,以下面这个为例,测试某接口发现被拦截。
以下面这个为例,测试某接口发现被拦截
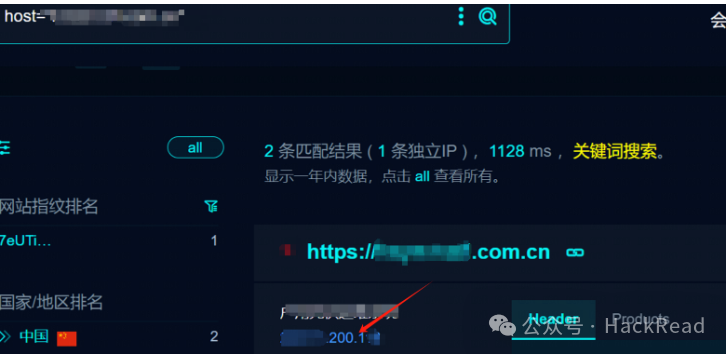
搜集ip信息为xxx.xxx.200.1xx
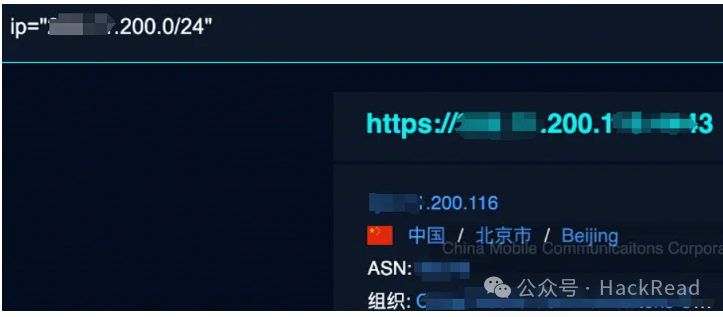
查找c段服务,一个个访问尝试
- 分块传输绕过WAF:利用分块传输吊打所有WAF、技术讨论 | 在HTTP协议层面绕过WAF、编写Burp分块传输插件绕WAF、Java反序列化数据绕WAF之延时分块传输
- 其他特性
- Mysql特性使用/!%0a/绕过
- 通过编码饶过
- 使用截断字符
- 重复变量
- 参数解析差异
- 针对域名的保护
- 对Content-Type不同理解
- 超大数据包
- Post不同解析方式
- 异常数据包
- 还有一些其他的绕过思路:
- 超长文件名:利用超长的文件名,可以逃过文件后缀名的检测
- 上传内容使用垃圾字符:上传一个比较大的文件,将马子藏在其中
- 使用参数污染成功执行命令:简而言之,就是给参数赋上多个值
- 构造畸形请求包:
有些可以通过修改POST为GET绕过waf
还有的waf通过Content-Type: multipart/form-data来判定这是个上传包,然后检测内容
这个方法,又能细分出很多来,而且屡试不爽,这里总结下我个人常用的
(1) 删掉content-type
(2) 构造多个filename
(3)content-type后面加TABLE键
(4)换行boundary
(5)文件名前面加空格
(6)文件名前面加单引号 - 文件内容编码绕过:既可以让waf检测不到,又能成功执行命令。
防守(蓝队)视角下的WAF
https://www.freebuf.com/articles/web/338908.html
WAF接入配置最佳实践
go-fast-waf
- WAF的配置与优化
- WAF规则配置
- WAF性能优化
- WAF与其他安全设备的联动
- WAF的局限性
- WAF无法防御所有攻击
- WAF可能引入新的安全风险
- WAF可能影响网站性能
- 蓝队常用的防御WAF绕过的手段
- WAF规则不断更新
- WAF与IDS/IPS联动
- WAF与Web应用防火墙联动
- 应用层防护
- WAF旁路部署
- 人工安全监测